頁數 1 / 2
下一頁
搜尋 搜尋 結果:
IIS 如果要使用 reverse proxy server 服務,其實網路上已經有很多文章可以參考
這篇文章只是記錄一下安裝上要注意的事
過去安裝 IIS 套件 可以透過 Web Platform Installer 搜尋下載
但現在 IIS 的 Web Platform Installer 已經不讓人搜尋下載可安裝的套件
所以要直接去微軟網站找相關套件 可以用 IIS ARR 搜尋
https://www.iis.net/downloads/microsoft/application-request-routing
下載 requestRouter_amd64.msi 安裝這個 (3.0版 2021 年以後就沒有更新了)
安裝前,IIS也要預先安裝 URLRewrite 2 套件
安裝很簡單,msi 安裝後,IIS重啟就可以看到
IIS 的主機設定,可以看到 "Application Reuest Routing Cache" --> 點進後右邊有 Server Proxy Settings
proxy 的設定有一些地方要注意一下,避免未來採到雷
首先 當然先開啟 Enable proxy,下面針對一些要注意的屬性說明一下
1. Time-out : 預設120秒,如果你後端的站台有一些操作可能超過兩分鐘(例如處理報表),這個就調長一點
2. Reverse rewrite host in response header: 這個勾勾預設是開的,他的好意是同站台redirect(302) 到其他網頁,可以覆蓋
host 讓 client端能跑到正常的網址。但如果你是 redirect 到其他站台,建議把它關掉,不然後端網站如果下
redirect (302) 到別的站台,他會主動把 redirect網址 host 改為本站 (被雷過,所以要特別記下來)
3. Include TCP port from client IP: 這是一個 X-Forwarded-For 設定,預設是打開,這樣後端主機抓 client 來源 IP就會類似
"112.121.100.100:443" ,但後端網站在抓 client端IP通常不會管 port number,因此就會造成比對 IP 發生錯誤
所以建議還是把它關閉
4. Enable disk cache: 預設是勾勾打開,如果後端是靜態網站,例如圖片server,這個打開沒有問題,但如果後端網站是動態網站
那還是關掉
這篇文章只是記錄一下安裝上要注意的事
過去安裝 IIS 套件 可以透過 Web Platform Installer 搜尋下載
但現在 IIS 的 Web Platform Installer 已經不讓人搜尋下載可安裝的套件
所以要直接去微軟網站找相關套件 可以用 IIS ARR 搜尋
https://www.iis.net/downloads/microsoft/application-request-routing
下載 requestRouter_amd64.msi 安裝這個 (3.0版 2021 年以後就沒有更新了)
安裝前,IIS也要預先安裝 URLRewrite 2 套件
安裝很簡單,msi 安裝後,IIS重啟就可以看到
IIS 的主機設定,可以看到 "Application Reuest Routing Cache" --> 點進後右邊有 Server Proxy Settings
proxy 的設定有一些地方要注意一下,避免未來採到雷
首先 當然先開啟 Enable proxy,下面針對一些要注意的屬性說明一下
1. Time-out : 預設120秒,如果你後端的站台有一些操作可能超過兩分鐘(例如處理報表),這個就調長一點
2. Reverse rewrite host in response header: 這個勾勾預設是開的,他的好意是同站台redirect(302) 到其他網頁,可以覆蓋
host 讓 client端能跑到正常的網址。但如果你是 redirect 到其他站台,建議把它關掉,不然後端網站如果下
redirect (302) 到別的站台,他會主動把 redirect網址 host 改為本站 (被雷過,所以要特別記下來)
3. Include TCP port from client IP: 這是一個 X-Forwarded-For 設定,預設是打開,這樣後端主機抓 client 來源 IP就會類似
"112.121.100.100:443" ,但後端網站在抓 client端IP通常不會管 port number,因此就會造成比對 IP 發生錯誤
所以建議還是把它關閉
4. Enable disk cache: 預設是勾勾打開,如果後端是靜態網站,例如圖片server,這個打開沒有問題,但如果後端網站是動態網站
那還是關掉
darren, 2025/1/10 上午 11:01:38
最近因為資安公司要求,要把 jQuery 升級到最新版
網路查了一下,似乎 3.5 版以後, XSS 才算是改善很多
目前最新版本是 3.7.0,對於原本就使用 3 以上版本專案影響就不大,所有 function 沿用上沒有問題
但是有些舊專案使用 2.X 甚至 1.X 升級到 3.7.0 版之後就會有些功能掛掉
經測試,首當其衝的就是 $(window).load 不能使用,更精準一點應該是 .load() 不能使用
檢查 jquery 過期網頁 https://api.jquery.com/category/deprecated/
發現 .load() 是 1.8 版以後 deprecated,但我 2.2.4 用很久用爽爽
我想應該是 jquery 為了相容問題,一直到跨版本才真的拿掉
也就是 1.X 宣告 deprecated 的功能,到 3.X 才真的移除
(請看附圖)
所以我就鴕鳥的找 1.X deprecated 然後可能會用的 function 處理
(若有 tag "Removed" 就是已移除,這樣找比較快)
大致上專案搜尋字串應該就能處理
但有些可能是其他第三方 jquery物件 例如 jquery-ui ,會用到以上功能
這時可能要去該物件看有無對應升級版
網路查了一下,似乎 3.5 版以後, XSS 才算是改善很多
目前最新版本是 3.7.0,對於原本就使用 3 以上版本專案影響就不大,所有 function 沿用上沒有問題
但是有些舊專案使用 2.X 甚至 1.X 升級到 3.7.0 版之後就會有些功能掛掉
經測試,首當其衝的就是 $(window).load 不能使用,更精準一點應該是 .load() 不能使用
檢查 jquery 過期網頁 https://api.jquery.com/category/deprecated/
發現 .load() 是 1.8 版以後 deprecated,但我 2.2.4 用很久用爽爽
我想應該是 jquery 為了相容問題,一直到跨版本才真的拿掉
也就是 1.X 宣告 deprecated 的功能,到 3.X 才真的移除
(請看附圖)
所以我就鴕鳥的找 1.X deprecated 然後可能會用的 function 處理
(若有 tag "Removed" 就是已移除,這樣找比較快)
.andSelf()
.live()
.die()
.error()
.load()
.unload()
.size()
.toggle()
大致上專案搜尋字串應該就能處理
但有些可能是其他第三方 jquery物件 例如 jquery-ui ,會用到以上功能
這時可能要去該物件看有無對應升級版
darren, 2023/7/20 上午 11:08:33
最近剛好發生跟 MS SQL 有關的狀況,所以就記錄一下
1. where 字串欄位要不要加 N'' (unicode)
範例: Select * from OrderDetail where OrderDetailId= N'20220923084533'
基本上,欄位是 char、varchar 就不需要。nvarchar nchar 就要加 N
這好像是廢話,但往往寫程式會沒注意,甚至是會覺得通通加 N 比較沒問題
但如果欄位牽涉到 index 就會影響搜尋 ,所以寫程式當下要注意
2. 當欄位有 null 值,where [clumnName] not in ('A') 也會排除 null 的狀況
直覺上,只要下 not in (..) 那會其他項目都會抓出,但是實際上,該欄位是 null的資料也會被排除
因為資料庫一旦你對某欄位下條件,他就會排除 null 的欄位,除非你指定 [clumnName] is null 才會有資料
1. where 字串欄位要不要加 N'' (unicode)
範例: Select * from OrderDetail where OrderDetailId= N'20220923084533'
基本上,欄位是 char、varchar 就不需要。nvarchar nchar 就要加 N
這好像是廢話,但往往寫程式會沒注意,甚至是會覺得通通加 N 比較沒問題
但如果欄位牽涉到 index 就會影響搜尋 ,所以寫程式當下要注意
-- 假設 OrderDetailId 是 varchar(20)
-- OrderDetail 有千萬筆資料
Select * from OrderDetail where OrderDetailId= N'20220923084533'
-- 結果跑超級久 (未使用 PK 找,掃整個 table)
Select * from OrderDetail where OrderDetailId= '20220923084533'
-- 結果一下就出來 (使用 PK 找)
-- **資料庫設計最好以數值來當 key 比較好
2. 當欄位有 null 值,where [clumnName] not in ('A') 也會排除 null 的狀況
直覺上,只要下 not in (..) 那會其他項目都會抓出,但是實際上,該欄位是 null的資料也會被排除
因為資料庫一旦你對某欄位下條件,他就會排除 null 的欄位,除非你指定 [clumnName] is null 才會有資料
darren, 2022/9/23 下午 04:06:22
上一集當中我們完成了Lucene基本操作中的Create與Read,這一集會將CRUD中的Update與Delete的操作方法告訴你,並且本集會著重於講解關於"Norms"與權重(Boost)在Lucene中的運作概念。
首先我們建立一個.Net 6的主控台應用程式
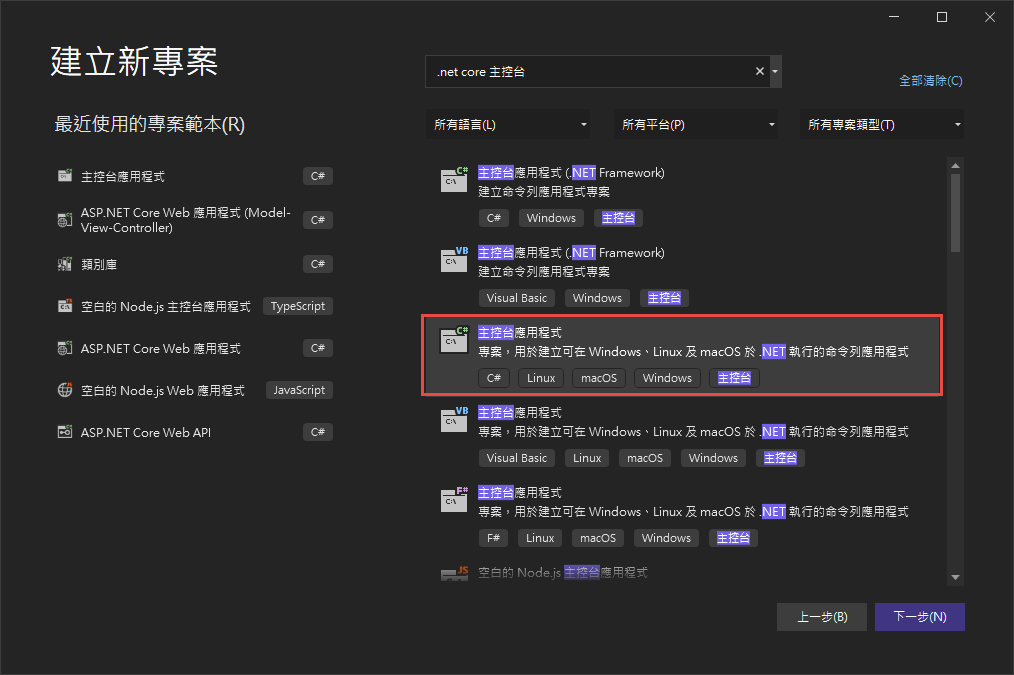
建立好後於右側專案右鍵選擇"管理Nuget套件",並選擇"瀏覽">於搜索列中搜尋"Lucene">安裝3.0.3最新穩定版 與 "System.Configuration.ConfigurationManager"
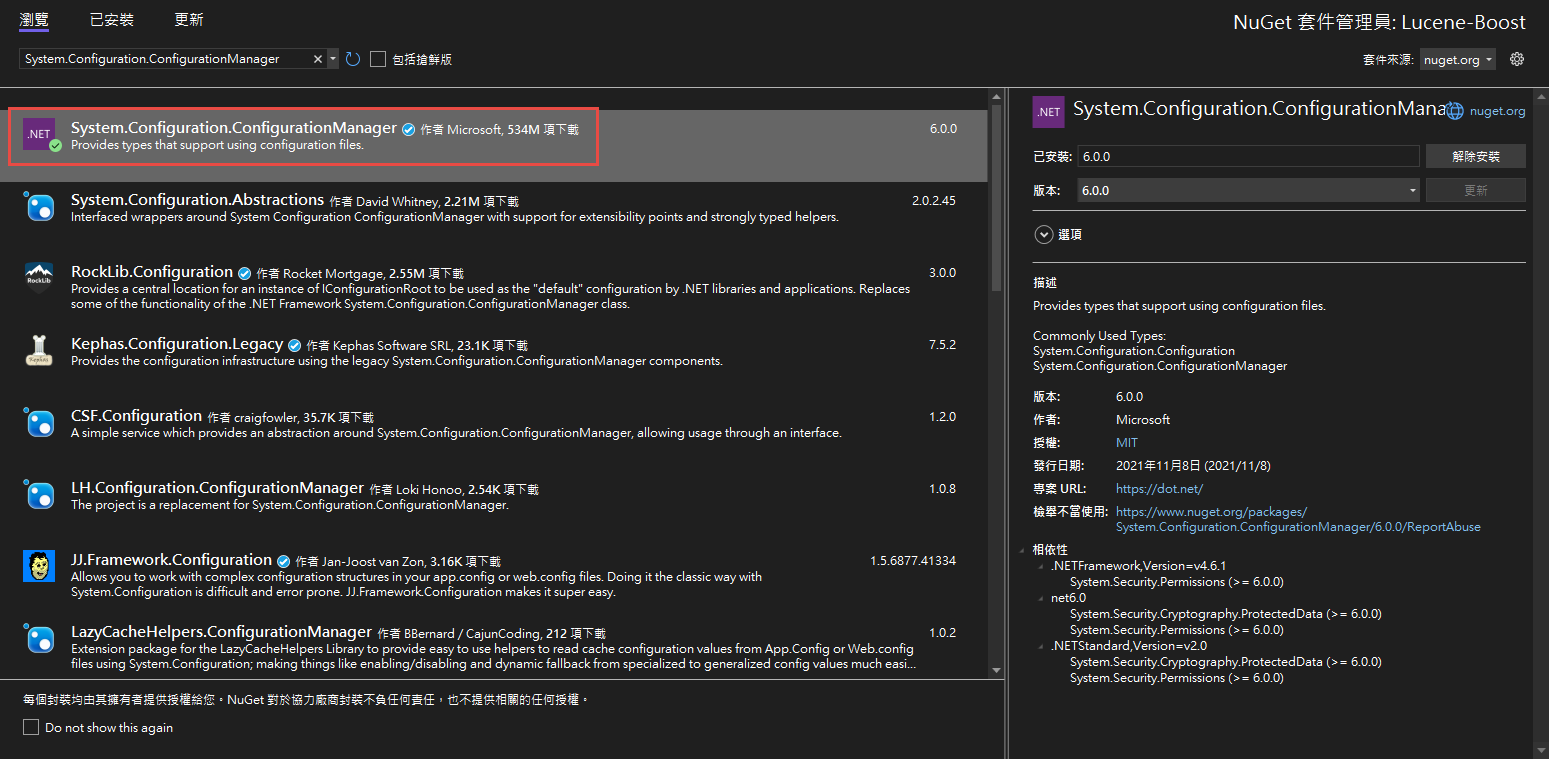
安裝好後就可以於專案內使用Lucene套件囉!
再來依照上一篇的教學建立一套簡單的Lucene查詢
好囉! 接下來我們要如何更新索引呢?
更新其實就是將存在的索引刪除並重新建立Document,不存在的則直接新增。
首先準備一組資料準備更新
*欲更新的Document必須與創建所引時使用的Document欄位相同*
來測試看看
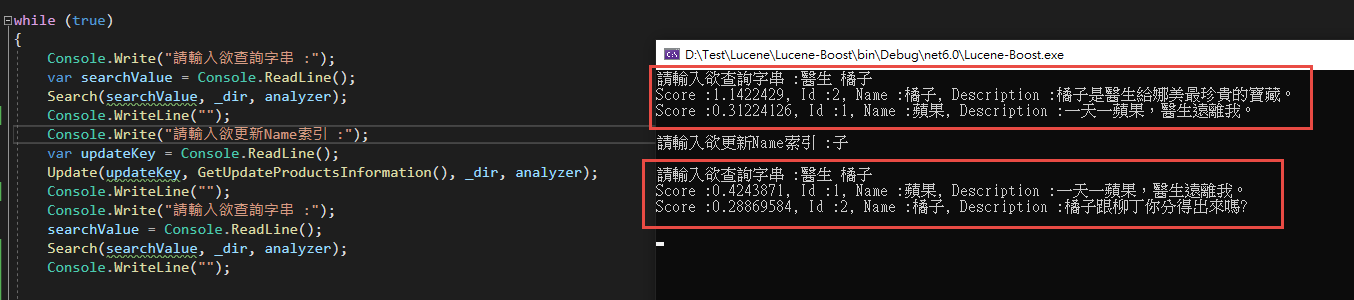
可以看見 Name = 橘子 的索引已經改為我們新準備的資料囉。
再來是刪除!
與更新非常相似,只需要使用deleteDocument()就可以了。
再來看看輸出結果
可以發現 Score :0.7554128, Id :2, Name :橘子, Description :醫生給娜美最珍貴的寶藏。這筆索引已經被移除囉!
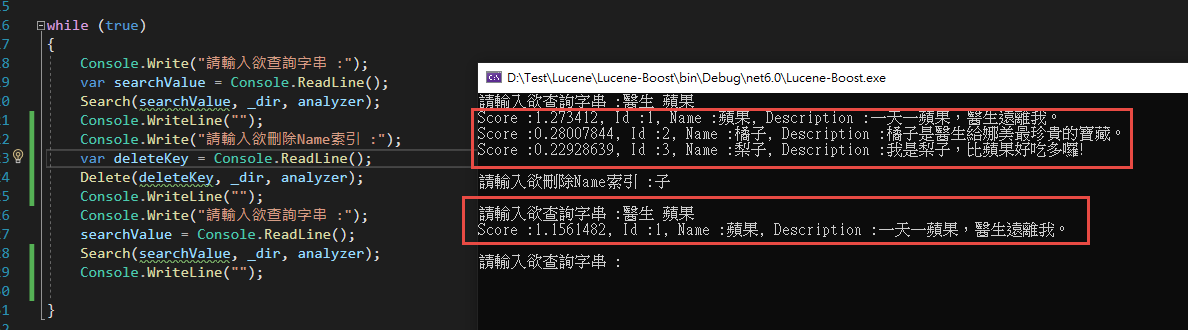
可以發現筆者於更新或刪除時都是輸入單一字來做異動,除了表達可以對索引做複合更動外,
是因為更新與刪除索引同樣會使用到分詞器(analyzer),
*所輸入的索引值非ID等數值時必須要配合分詞器的分詞能力*才能取得所想異動的索引喔!
Boost是什麼呢?
Boost 分為 :
1. Index Time Boost : 在建立索引時就計算好的值。例如上一篇中提到的(NORMS)
2. Query Time Boost : 查詢時賦與搜尋條件不同的值以影響結果。
我們先來測試Index Time Boost的部分
並記得重新CreateIndex才能刷新欄位的權重值喔。
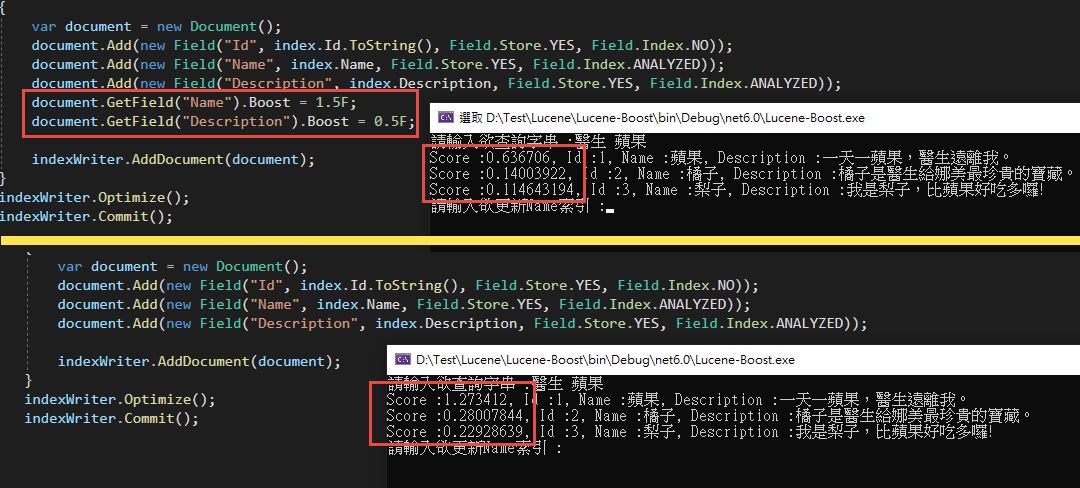
很明顯的搜尋出來的Score分數變動了! 但是有沒有發現明明Name欄位的Boost改成了1.5,蘋果的數值卻仍然只有一半呢?
這是因為我們的Search中所參照的欄位為Description,所以在計算Score的時候其實是完全沒有參與的喔!
另外要記得,使用Index Time Boost的時候,欲給予銓重分配的欄位Field.Index不能使用NO_NORMS,不然這個欄位並不會紀錄權重的資料。
再來我們試試看Query Time Boost
這次我們搜尋兩個欄位"Name"與"Description",並使用 BooleanQuery來將其組合。
BooleanQuery中的 Occur有三種參數 : "MUST","MUST_NOT","SHOULD",功能與字面上的意思一樣為"必須要有","必須沒有"與"有無都包含"。

查詢出來的分數就不一樣囉!
以上就是這一次的分享,Lucene是一款容易入門但是要實際上戰場卻又十分複雜的功能,想要達成真正高效能的全文檢索,在前期的文件規畫配置與資料的權重配比都是一個巨大的挑戰。未來會繼續分享關於Lucene的其他有趣功能,還請繼續期待呦!
另外也可以到GitHub下載我的範例來參考呦!
GitHub: https://github.com/g13579112000/Lucene
參考文件:
1. 黑暗大大的全文檢索筆記 : https://blog.darkthread.net/blog/lucene-net-notes-1/
2. Makble : http://makble.com/lucene-field-boost-example
3. CSDN Jack2013tong 文章 : https://blog.csdn.net/huwei2003/article/details/53408388
首先我們建立一個.Net 6的主控台應用程式
建立好後於右側專案右鍵選擇"管理Nuget套件",並選擇"瀏覽">於搜索列中搜尋"Lucene">安裝3.0.3最新穩定版 與 "System.Configuration.ConfigurationManager"
安裝好後就可以於專案內使用Lucene套件囉!
再來依照上一篇的教學建立一套簡單的Lucene查詢
using Lucene.Net.Analysis.Standard;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.QueryParsers;
using Lucene.Net.Search;
using Lucene.Net.Store;
var _dir = new DirectoryInfo("LuceneDocument");
if (!File.Exists(_dir.FullName))
{
System.IO.Directory.CreateDirectory(_dir.FullName);
}
var analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_CURRENT);
CreateIndex(GetProductsInformation(), _dir, analyzer);
while (true)
{
Console.Write("請輸入欲查詢字串 :");
var searchValue = Console.ReadLine();
Search(searchValue, _dir, analyzer);
}
void CreateIndex(List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
void Search(string searchValue, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(_dir))
{
var parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
using (var indexSearcher = new IndexSearcher(directory))
{
var queryLimit = 20;
var hits = indexSearcher.Search(parser, queryLimit);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
}
}
}
List<Product> GetProductsInformation()
{
return new List<Product> {
new Product{ Id = 1, Name = "蘋果", Description = "一天一蘋果,醫生遠離我。"},
new Product{ Id = 2, Name = "橘子", Description = "醫生給娜美最珍貴的寶藏。"},
new Product{ Id = 3, Name = "梨子", Description = "我是梨子,比蘋果好吃多囉!"},
new Product{ Id = 4, Name = "葡萄", Description = "吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮"},
new Product{ Id = 5, Name = "榴槤", Description = "水果界的珍寶!好吃一直吃。"}
};
}
class Product
{
public long Id { get; set; }
public string Name { get; set; } = null!;
public string Description { get; set; } = null!;
}
好囉! 接下來我們要如何更新索引呢?
更新其實就是將存在的索引刪除並重新建立Document,不存在的則直接新增。
首先準備一組資料準備更新
List<Product> GetUpdateProductsInformation()
{
return new List<Product>
{
new Product{ Id = 6, Name = "香蕉", Description = "運動完後吃根香蕉補充養分。"},
new Product{ Id = 2, Name = "橘子", Description = "橘子跟柳丁你分得出來嗎?"}
};
}
*欲更新的Document必須與創建所引時使用的Document欄位相同*
void Update(string key, List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using( var directory = FSDirectory.Open(dir))
{
using(var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
indexWriter.UpdateDocument(new Term("Name", key) ,document);
}
}
}
}
來測試看看
可以看見 Name = 橘子 的索引已經改為我們新準備的資料囉。
再來是刪除!
與更新非常相似,只需要使用deleteDocument()就可以了。
void Delete(string key, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
indexWriter.DeleteDocuments(new Term("Name", key));
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
再來看看輸出結果
可以發現 Score :0.7554128, Id :2, Name :橘子, Description :醫生給娜美最珍貴的寶藏。這筆索引已經被移除囉!
可以發現筆者於更新或刪除時都是輸入單一字來做異動,除了表達可以對索引做複合更動外,
是因為更新與刪除索引同樣會使用到分詞器(analyzer),
*所輸入的索引值非ID等數值時必須要配合分詞器的分詞能力*才能取得所想異動的索引喔!
Boost是什麼呢?
Boost 分為 :
1. Index Time Boost : 在建立索引時就計算好的值。例如上一篇中提到的(NORMS)
2. Query Time Boost : 查詢時賦與搜尋條件不同的值以影響結果。
我們先來測試Index Time Boost的部分
void CreateIndexWithBoost(List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
document.GetField("Name").Boost = 1.5F;
document.GetField("Description").Boost = 0.5F;
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
並記得重新CreateIndex才能刷新欄位的權重值喔。
很明顯的搜尋出來的Score分數變動了! 但是有沒有發現明明Name欄位的Boost改成了1.5,蘋果的數值卻仍然只有一半呢?
這是因為我們的Search中所參照的欄位為Description,所以在計算Score的時候其實是完全沒有參與的喔!
另外要記得,使用Index Time Boost的時候,欲給予銓重分配的欄位Field.Index不能使用NO_NORMS,不然這個欄位並不會紀錄權重的資料。
再來我們試試看Query Time Boost
void SearchWithBoost(string searchValue, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(_dir))
{
using (var indexSearcher = new IndexSearcher(directory))
{
var query = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Name", analyzer).Parse(searchValue);
var query2 = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
query.Boost = 2.0F;
query2.Boost = 0.5F;
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.Add(query, Occur.SHOULD);
booleanQuery.Add(query2, Occur.SHOULD);
var hits = indexSearcher.Search(booleanQuery, 20);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
}
}
}
這次我們搜尋兩個欄位"Name"與"Description",並使用 BooleanQuery來將其組合。
BooleanQuery中的 Occur有三種參數 : "MUST","MUST_NOT","SHOULD",功能與字面上的意思一樣為"必須要有","必須沒有"與"有無都包含"。
查詢出來的分數就不一樣囉!
以上就是這一次的分享,Lucene是一款容易入門但是要實際上戰場卻又十分複雜的功能,想要達成真正高效能的全文檢索,在前期的文件規畫配置與資料的權重配比都是一個巨大的挑戰。未來會繼續分享關於Lucene的其他有趣功能,還請繼續期待呦!
另外也可以到GitHub下載我的範例來參考呦!
GitHub: https://github.com/g13579112000/Lucene
參考文件:
1. 黑暗大大的全文檢索筆記 : https://blog.darkthread.net/blog/lucene-net-notes-1/
2. Makble : http://makble.com/lucene-field-boost-example
3. CSDN Jack2013tong 文章 : https://blog.csdn.net/huwei2003/article/details/53408388
梨子, 2022/4/20 下午 09:34:03
首先尋找出一支欲調效的Table或Query
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
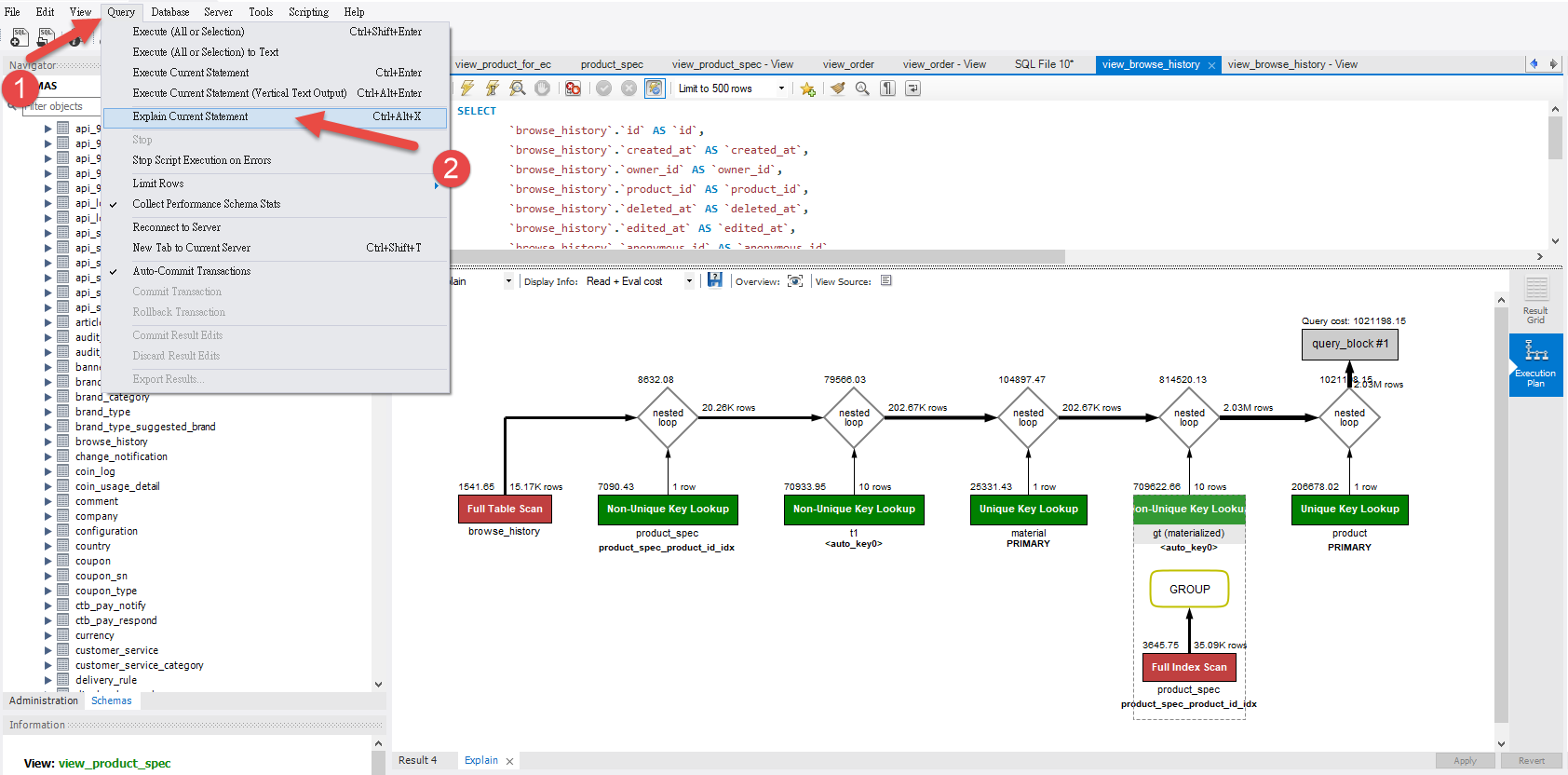
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
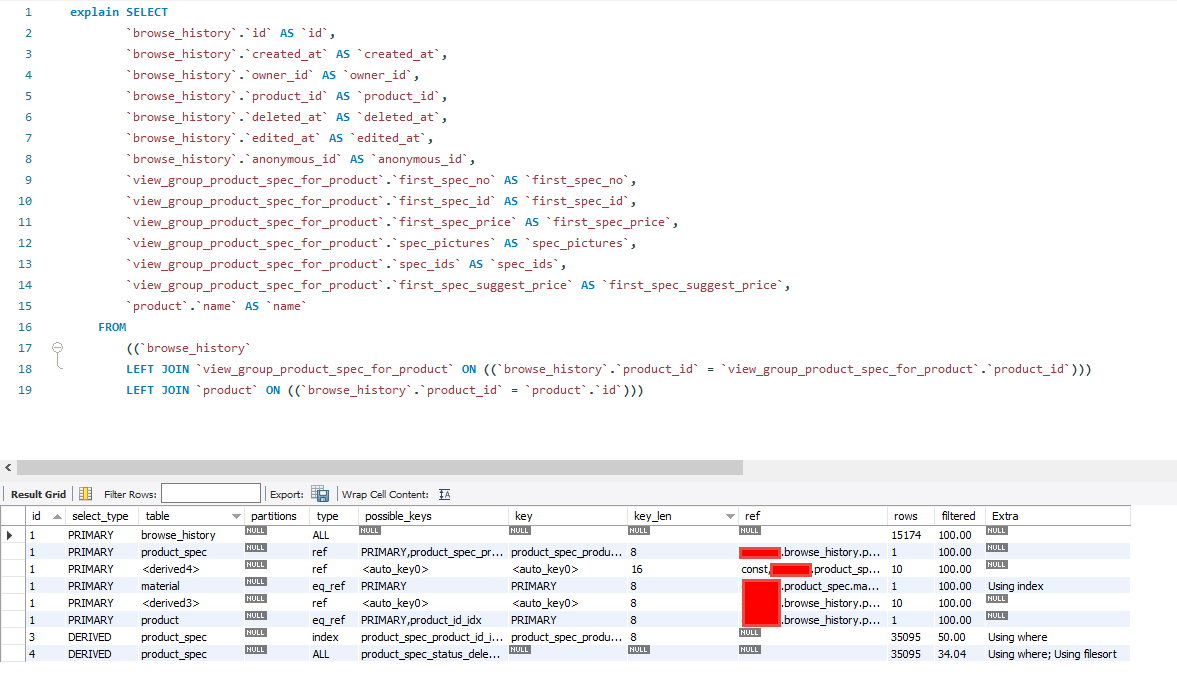
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
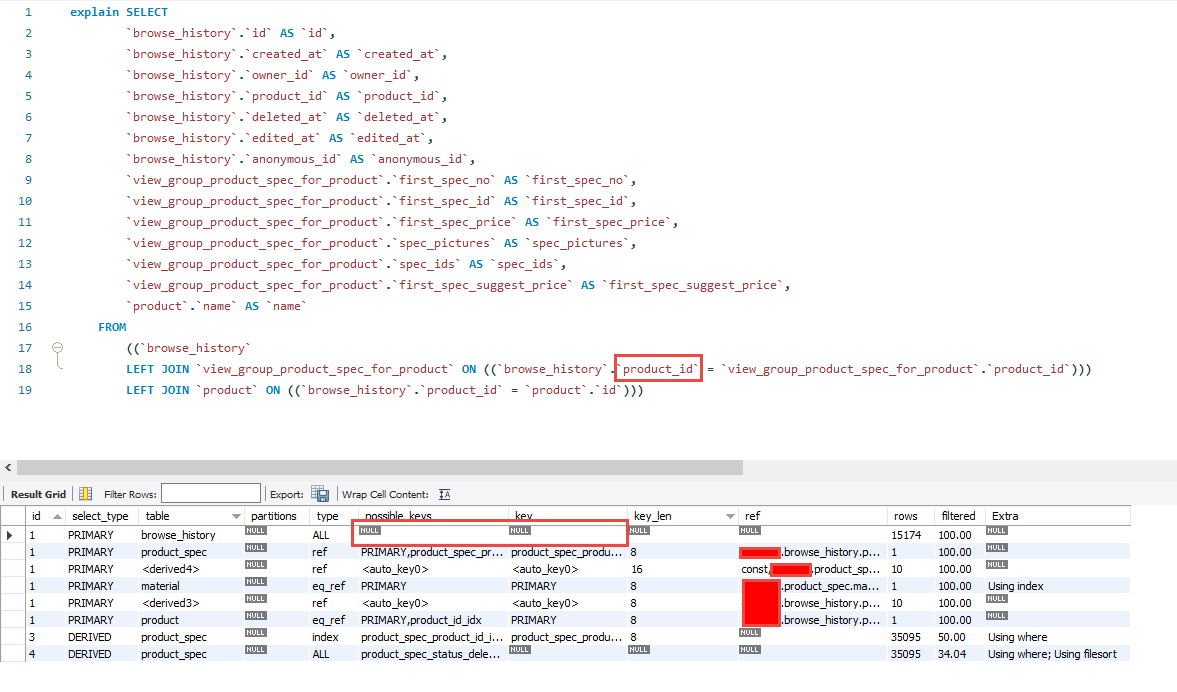
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
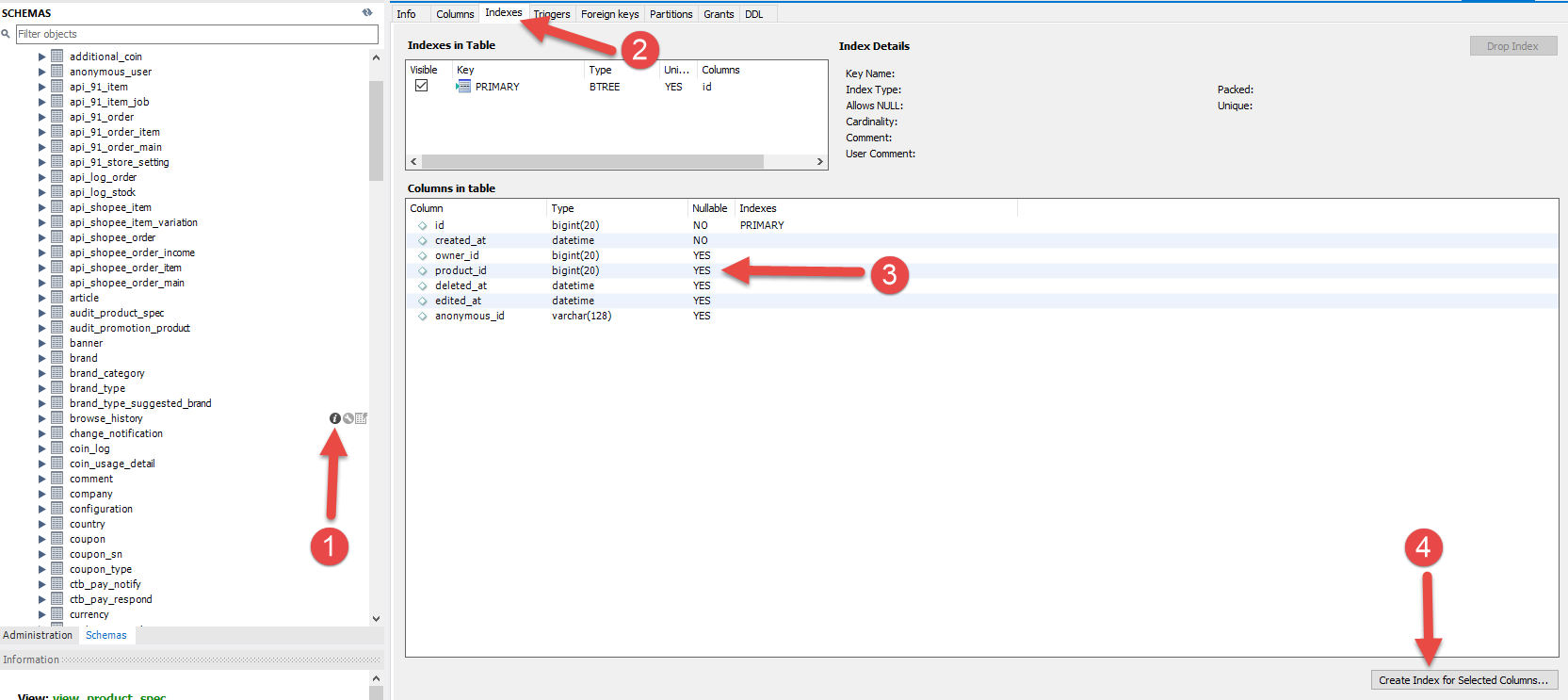
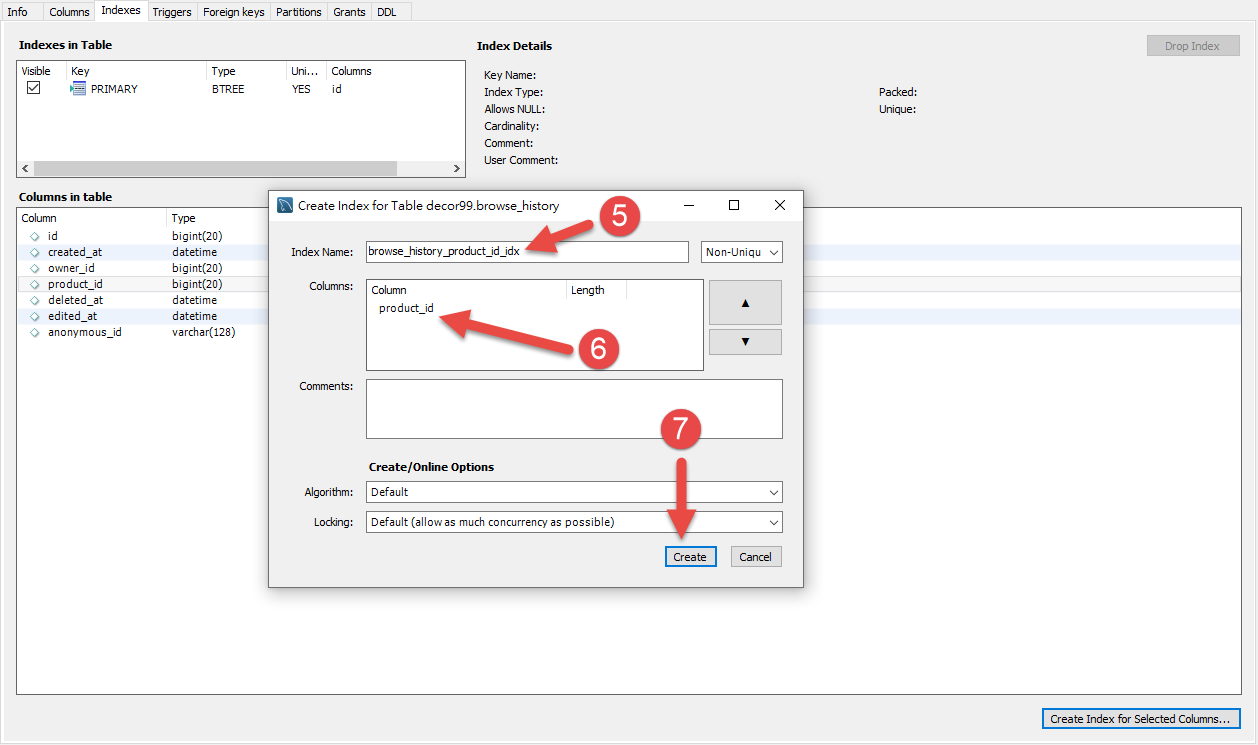
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
梨子, 2022/3/28 下午 09:00:29
Lucene.Net是一套C#開源全文索引庫,其主要包含了:
· Index : 提供索引的管理與詞組的排序
· Search : 提供查詢相關功能
· Store : 支援資料儲存管理,包括I/O操作
· Util : 共用套件
· Documents : 負責描述索引儲存時的文件結構管理
· QueryParsers : 提供查詢語法
· Analysis : 負責分析內容
要達到高效能的全文檢索讓機器可以明白我們的語言,最重要的關鍵就是"分詞器"了。
試想一下這一句話你會如何拆分成一段一段的關鍵字呢?
"一天一蘋果,醫生遠離我"
還有英文版本
"An apple a day, doctor keep me away."
中文版本的拆分:
"一天"、"一"、"蘋果"、"醫生"、"遠離"、"我"
英文版本的拆分:
"apple"、"day"、"doctor"、"keep"、"me"、"away"
有沒有注意到不同語系所分析出來的關鍵字有一點不一樣呢?
而在Lucene中分詞的工作會交給Analysis來完成,
不過我們可以依照不同的語系去選擇想使用的分詞器(Analyzer)!
首先簡單說明一下Lucene的實作流程
1. 確認主要搜尋的語系來決定使用的分詞器(analyzer)
2. 建立Document依照analyzer匯入資料
(前置完成)
3. 建立IndexSearcher導入準備好的Document
4. 建立Parser來分析SearchValue
5. 使用IndexSearcher分析Parser取得結果(Hits)
*本專案使用的是Lucene.Net 3.0.3*
接下來我們來建立一個提供查詢使用的Document。
如此一來我們就建立好Lucene的基本配備囉!
其中analyzer的部分我們使用Lucene.Net預設,
要特別注意的是,其處理中文語系的能力非常之爛!
之後再寫一篇文章深入探討。
再來值得一提的是
前兩個參數就是Key跟Value,可以簡單理解為欄位與其內容。
後面兩個參數是重點!
Store: 代表是否儲存這個Key的Value
例如在google打上台南美食會搜索出許多不同的文章連結,
不過google給你的資料中最重要的不是文章內容(Description),
而是哪一篇文章(Name)與台南美食最有關係。
假如今天我只要回傳一個列表而不用提示文章中有哪些內容,
那麼我就可以選擇給"Description" Field.Store.No來節省空間。
Index:
· NO - 不加入索引,這個內容只需要隨著結果出爐,不需要在查詢的時候被考慮。
· ANALYZED、NOT_ANALYZED - 是否使用分詞
· NO_NORMS - 關閉權重功能
或許許多人會對權重功能(NORMS)感到疑惑,
簡單的舉個例子
{ Id=1, Key="蘋果", Value="一天一蘋果,醫生遠離我。"}
{ Id=2, Key="橘子", Value="醫生給娜美最珍貴的寶藏。"}
{ Id=3, Key="梨子", Value="我是梨子,比蘋果蘋果好吃多囉!"}
當我搜尋"蘋果"的時候結果會是
{ Id=1, MatchKey=1, MatchValue=1, Score=(1*5) + (1*2) = 7}
{ Id=3, MatchKey=0, MatchValue=1, Score=(0*5) + (2*2) = 4}
有發現了嗎?
雖然同樣都對中兩個結果但是Id 1的資料Key值中有包含關鍵字,
因此得到較高的分數排在Id 3前方
準備好Document了,我們可以開始來實際使用看看囉!
最後的結果(Hits),是需要再回到Document去撈出對應的資料喔!
是不是非常簡單呢?
筆者寫了一個簡單的範例在GitHub上,秉持著追求新技術的心使用了.Net 6,還請各位大大多多包涵。
有中英文兩種Repository,只需要在上方的DI注入切換就可以囉!
GitHub連結: https://github.com/g13579112000/Lucene
筆者第一次撰寫這種教學文章,有哪邊錯誤的非常歡迎一起來討論指教。
之後有機會再撰寫Lucene更深入的應用方面,
例如權重的分配與分詞器的選擇與使用。
感謝您的閱讀。
參考文獻:
1.黑暗大大的全文檢索筆記: https://blog.darkthread.net/blog/lucene-net-notes-1/
2.使用.Net實現全文檢索: https://blog.csdn.net/huwei2003/article/details/53408388
3.伊凡的部落格: http://irfen.me/5-lucene4-9-learning-record-lucene-analysis-tokenizer/
4.純淨天空代碼範例: https://vimsky.com/zh-tw/examples/detail/csharp-ex-Lucene.Net.Documents-Document---class.html
· Index : 提供索引的管理與詞組的排序
· Search : 提供查詢相關功能
· Store : 支援資料儲存管理,包括I/O操作
· Util : 共用套件
· Documents : 負責描述索引儲存時的文件結構管理
· QueryParsers : 提供查詢語法
· Analysis : 負責分析內容
要達到高效能的全文檢索讓機器可以明白我們的語言,最重要的關鍵就是"分詞器"了。
試想一下這一句話你會如何拆分成一段一段的關鍵字呢?
"一天一蘋果,醫生遠離我"
還有英文版本
"An apple a day, doctor keep me away."
中文版本的拆分:
"一天"、"一"、"蘋果"、"醫生"、"遠離"、"我"
英文版本的拆分:
"apple"、"day"、"doctor"、"keep"、"me"、"away"
有沒有注意到不同語系所分析出來的關鍵字有一點不一樣呢?
而在Lucene中分詞的工作會交給Analysis來完成,
不過我們可以依照不同的語系去選擇想使用的分詞器(Analyzer)!
首先簡單說明一下Lucene的實作流程
1. 確認主要搜尋的語系來決定使用的分詞器(analyzer)
2. 建立Document依照analyzer匯入資料
(前置完成)
3. 建立IndexSearcher導入準備好的Document
4. 建立Parser來分析SearchValue
5. 使用IndexSearcher分析Parser取得結果(Hits)
*本專案使用的是Lucene.Net 3.0.3*
接下來我們來建立一個提供查詢使用的Document。
// 取得或建立Lucene文件資料夾
if (!File.Exists(_dir.FullName))
{
System.IO.Directory.CreateDirectory(_dir.FullName);
}
// Asp.Net Core需要於Nuget安裝System.Configuration.ConfigurationManager提供用戶端應用程式的組態檔存取
Lucene.Net.Store.Directory directory = FSDirectory.Open(_dir);
// 選擇分詞器
var analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_CURRENT);
// 資料來源
var repository = new Repository();
// 依照指定的文件結構來建立
var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);
foreach (var index in repository)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.NO, Field.Index.ANALYZED));
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
indexWriter.Dispose();
如此一來我們就建立好Lucene的基本配備囉!
其中analyzer的部分我們使用Lucene.Net預設,
要特別注意的是,其處理中文語系的能力非常之爛!
之後再寫一篇文章深入探討。
再來值得一提的是
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));前兩個參數就是Key跟Value,可以簡單理解為欄位與其內容。
後面兩個參數是重點!
Store: 代表是否儲存這個Key的Value
例如在google打上台南美食會搜索出許多不同的文章連結,
不過google給你的資料中最重要的不是文章內容(Description),
而是哪一篇文章(Name)與台南美食最有關係。
假如今天我只要回傳一個列表而不用提示文章中有哪些內容,
那麼我就可以選擇給"Description" Field.Store.No來節省空間。
Index:
· NO - 不加入索引,這個內容只需要隨著結果出爐,不需要在查詢的時候被考慮。
· ANALYZED、NOT_ANALYZED - 是否使用分詞
· NO_NORMS - 關閉權重功能
或許許多人會對權重功能(NORMS)感到疑惑,
簡單的舉個例子
{ Id=1, Key="蘋果", Value="一天一蘋果,醫生遠離我。"}
{ Id=2, Key="橘子", Value="醫生給娜美最珍貴的寶藏。"}
{ Id=3, Key="梨子", Value="我是梨子,比蘋果蘋果好吃多囉!"}
當我搜尋"蘋果"的時候結果會是
{ Id=1, MatchKey=1, MatchValue=1, Score=(1*5) + (1*2) = 7}
{ Id=3, MatchKey=0, MatchValue=1, Score=(0*5) + (2*2) = 4}
有發現了嗎?
雖然同樣都對中兩個結果但是Id 1的資料Key值中有包含關鍵字,
因此得到較高的分數排在Id 3前方
準備好Document了,我們可以開始來實際使用看看囉!
// 決定所要搜索的欄位
var parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
// 提供剛剛建立的Document
var indexSearcher = new IndexSearcher(directory);
// 搜尋取出結果的數量
var queryLimit = 20;
// 開始搜尋!
var hits = indexSearcher.Search(parser, queryLimit);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
最後的結果(Hits),是需要再回到Document去撈出對應的資料喔!
是不是非常簡單呢?
筆者寫了一個簡單的範例在GitHub上,秉持著追求新技術的心使用了.Net 6,還請各位大大多多包涵。
有中英文兩種Repository,只需要在上方的DI注入切換就可以囉!
GitHub連結: https://github.com/g13579112000/Lucene
筆者第一次撰寫這種教學文章,有哪邊錯誤的非常歡迎一起來討論指教。
之後有機會再撰寫Lucene更深入的應用方面,
例如權重的分配與分詞器的選擇與使用。
感謝您的閱讀。
參考文獻:
1.黑暗大大的全文檢索筆記: https://blog.darkthread.net/blog/lucene-net-notes-1/
2.使用.Net實現全文檢索: https://blog.csdn.net/huwei2003/article/details/53408388
3.伊凡的部落格: http://irfen.me/5-lucene4-9-learning-record-lucene-analysis-tokenizer/
4.純淨天空代碼範例: https://vimsky.com/zh-tw/examples/detail/csharp-ex-Lucene.Net.Documents-Document---class.html
梨子, 2022/2/24 下午 08:23:46
1. 建立 API Server
.Net 6.0
.Cross Site
.無 Session
.評分機制
2. 前端修改
. 改寫內容頁及編輯頁
. 使用 Vue 及 API
. 增加評分功能
. 上傳圖片問題處理
. 搜尋改用 Google Site Sarch
.Net 6.0
.Cross Site
.無 Session
.評分機制
2. 前端修改
. 改寫內容頁及編輯頁
. 使用 Vue 及 API
. 增加評分功能
. 上傳圖片問題處理
. 搜尋改用 Google Site Sarch
Bike, 2022/1/11 下午 12:05:09
這次因為小三美日要架設新機房設備,所以採用政府GPO的群組原則來提升安全性,關於設定的方式可由以下的附檔內說明使用,
在安裝GPO後,會遇到的問題及解決方式如下
1. 在安裝後發現原先預設使用的administrator帳號被停用,導致無法登入。
解決:在安裝GPO前,先換一個新的管理權限帳號即可
2. 想要安裝IIS或是hyper-v(新增角色)時,發現安裝權限已被停用。
解決:先搜尋到gpedit.msc,檢查電腦設定 \ 系統管理範本 \ Windows元件 \ Windowsl遠端殼層 \ 允許遠端殼層存取,是否為 已啟用
3.使用hyper-v安裝windows,再安裝GPO後,發現無法從hyper-v的console登入。
解決:搜尋gpedit.msc,檢查電腦設定 \ windows設定 \ 安全性設定 \ 使用者權限指派 \ 拒絕透過遠端桌面服務登入,移除本機帳戶
4.使用hyper-v配合GPO會無法將本機的資源(檔案)丟到虛擬主機。
解決:檢查電腦設定 \ 系統管理範本 \ windows 元件 \ 遠端桌面服務 \ 遠端桌面工作階段主機 \ 裝置及資源重新導向,將不允許磁碟機重新導向,設定為已停用
另外,搜尋gpedit.msc,檢查電腦設定 \ windows設定 \ 安全性設定 \ 使用者權限指派 \ 拒絕從網路存取這台電腦,移除管理權限帳戶
以上設定完後,最好在自己系統的cmd中,輸入gpupdate /force,直接更新原則
在安裝GPO後,會遇到的問題及解決方式如下
1. 在安裝後發現原先預設使用的administrator帳號被停用,導致無法登入。
解決:在安裝GPO前,先換一個新的管理權限帳號即可
2. 想要安裝IIS或是hyper-v(新增角色)時,發現安裝權限已被停用。
解決:先搜尋到gpedit.msc,檢查電腦設定 \ 系統管理範本 \ Windows元件 \ Windowsl遠端殼層 \ 允許遠端殼層存取,是否為 已啟用
3.使用hyper-v安裝windows,再安裝GPO後,發現無法從hyper-v的console登入。
解決:搜尋gpedit.msc,檢查電腦設定 \ windows設定 \ 安全性設定 \ 使用者權限指派 \ 拒絕透過遠端桌面服務登入,移除本機帳戶
4.使用hyper-v配合GPO會無法將本機的資源(檔案)丟到虛擬主機。
解決:檢查電腦設定 \ 系統管理範本 \ windows 元件 \ 遠端桌面服務 \ 遠端桌面工作階段主機 \ 裝置及資源重新導向,將不允許磁碟機重新導向,設定為已停用
另外,搜尋gpedit.msc,檢查電腦設定 \ windows設定 \ 安全性設定 \ 使用者權限指派 \ 拒絕從網路存取這台電腦,移除管理權限帳戶
以上設定完後,最好在自己系統的cmd中,輸入gpupdate /force,直接更新原則
nelson, 2020/9/16 上午 07:29:19
今天發生一個SQL奇怪的現象,記錄一下
就是訂單列表(使用分頁的SQL 找出 top 20)跑很久才出來,大約10多秒
SQL指令條件僅有訂單日期(預設是1年內訂單,訂單總數有130萬筆),而訂單日期也有做index
之前都大約1~2秒就出來,這一兩天卻要10秒才跑出來
用執行計畫評估功能查也看不出哪裡有問題,把一些子查詢拿掉也沒有改善
所以就改一下搜尋條件,改搜尋半年內訂單,大約 5秒
改搜尋兩年內訂單,1秒!!! 真是神奇,把條件區間拉大反而很快???????
直覺上覺得索引table是不是太大太亂了,剛好看到CreateDate索引有個重建按鈕
就勇敢把他按下去,想說會不會跑很久,結果重建只要不到1秒就好了
然後神奇的事發生了,訂單列表不須一秒就顯示出來啦!
SQL 指令大概長這樣
參考 will will web 的舊文章,原來定期把索引整理整理,也是要記得做的。
不過週期上我想 1季或半年跑一次應該就可以了
-------------------------------------------------------------------
後記: 2020/6/22 - 一年後又發生一樣的狀況,真是神奇
這次 OrderMain CreateDate 沒有很分散。只有 2.X %
想說其他 index 是不是該重建,但是都沒有效果
最後只好重建 CreateDate --> 結果居然解決了
看 2021年會在發生嗎?
就是訂單列表(使用分頁的SQL 找出 top 20)跑很久才出來,大約10多秒
SQL指令條件僅有訂單日期(預設是1年內訂單,訂單總數有130萬筆),而訂單日期也有做index
之前都大約1~2秒就出來,這一兩天卻要10秒才跑出來
用執行計畫評估功能查也看不出哪裡有問題,把一些子查詢拿掉也沒有改善
所以就改一下搜尋條件,改搜尋半年內訂單,大約 5秒
改搜尋兩年內訂單,1秒!!! 真是神奇,把條件區間拉大反而很快???????
直覺上覺得索引table是不是太大太亂了,剛好看到CreateDate索引有個重建按鈕
就勇敢把他按下去,想說會不會跑很久,結果重建只要不到1秒就好了
然後神奇的事發生了,訂單列表不須一秒就顯示出來啦!
SQL 指令大概長這樣
Select * from (
Select Top 20 * from (
select Top 20 a.*
--, CompelteOrderId= (select top 1 K.Id from packing_list_main k With(NoLock) join Order_Main p With(NoLock) on k.Order_Id=p.Id where k.En_Packing_List_Status=300 and P.MEmber_Id=a.Member_Id )
--, [MemoCount_前台問題] = (Select COUNT(*) from Order_Memo With(NoLock) where Order_Memo.Order_Id = a.Id and Memo_Type = 1)
--, [MemoCount_業務備註] = (Select COUNT(*) from Order_Memo With(NoLock) where Order_Memo.Order_Id = a.Id and Memo_Type = 3)
--, [MemoCount_系統檢查] = (Select COUNT(*) from Order_Memo With(NoLock) where Order_Memo.Order_Id = a.Id and Memo_Type = 4)
--, QnACount = (select count(*) from Order_QnA With(NoLock) where Order_Id = a.Id)
from V_Order_Main_For_Admin_List a With(NoLock) left join Member b with(NoLock) on a.Member_Id=b.Id where (1=1) and En_Order_Status <> -300 and a.Create_Date >='2018-06-20' order by Id Desc
) AS T1 order by Id
) AS T2 order by Id Desc
參考 will will web 的舊文章,原來定期把索引整理整理,也是要記得做的。
不過週期上我想 1季或半年跑一次應該就可以了
-------------------------------------------------------------------
後記: 2020/6/22 - 一年後又發生一樣的狀況,真是神奇
這次 OrderMain CreateDate 沒有很分散。只有 2.X %
想說其他 index 是不是該重建,但是都沒有效果
最後只好重建 CreateDate --> 結果居然解決了
看 2021年會在發生嗎?
darren, 2019/6/21 上午 12:05:00
success: 新增, 編輯
info: 搜尋, 匯出, 回列表, 檢視
primary: 清除, 取消, Reset
danger: 刪除
info: 搜尋, 匯出, 回列表, 檢視
primary: 清除, 取消, Reset
danger: 刪除
Bike, 2019/5/2 下午 02:46:40