搜尋 472 結果:




首先尋找出一支欲調效的Table或Query
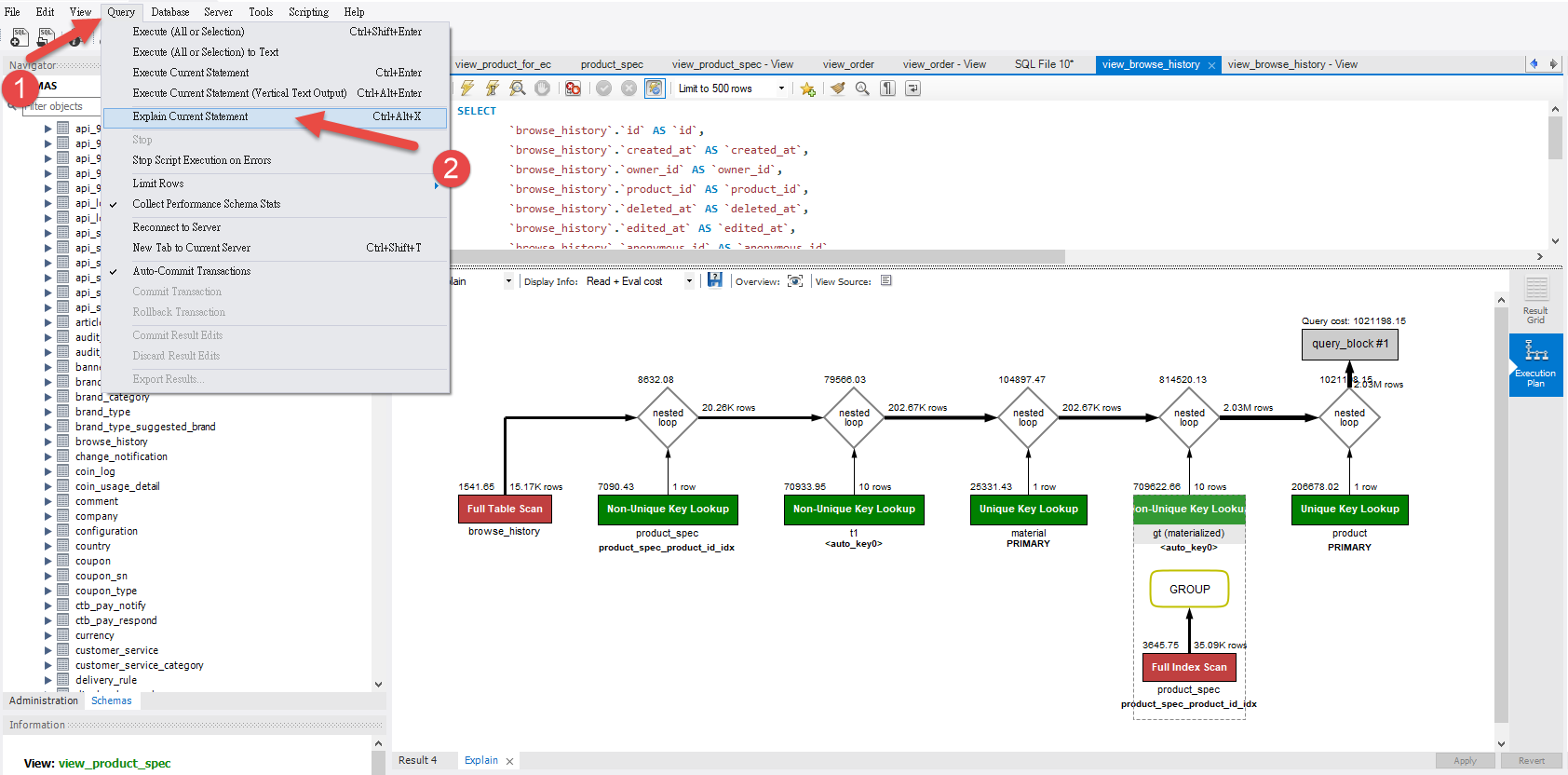
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
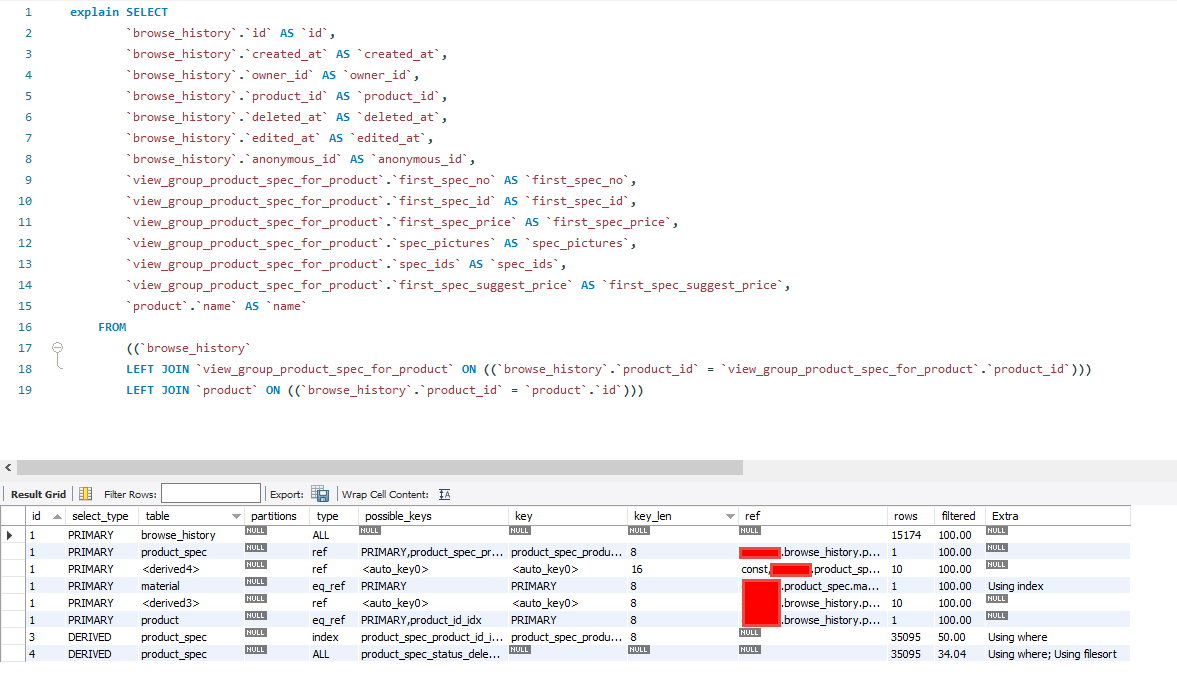
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
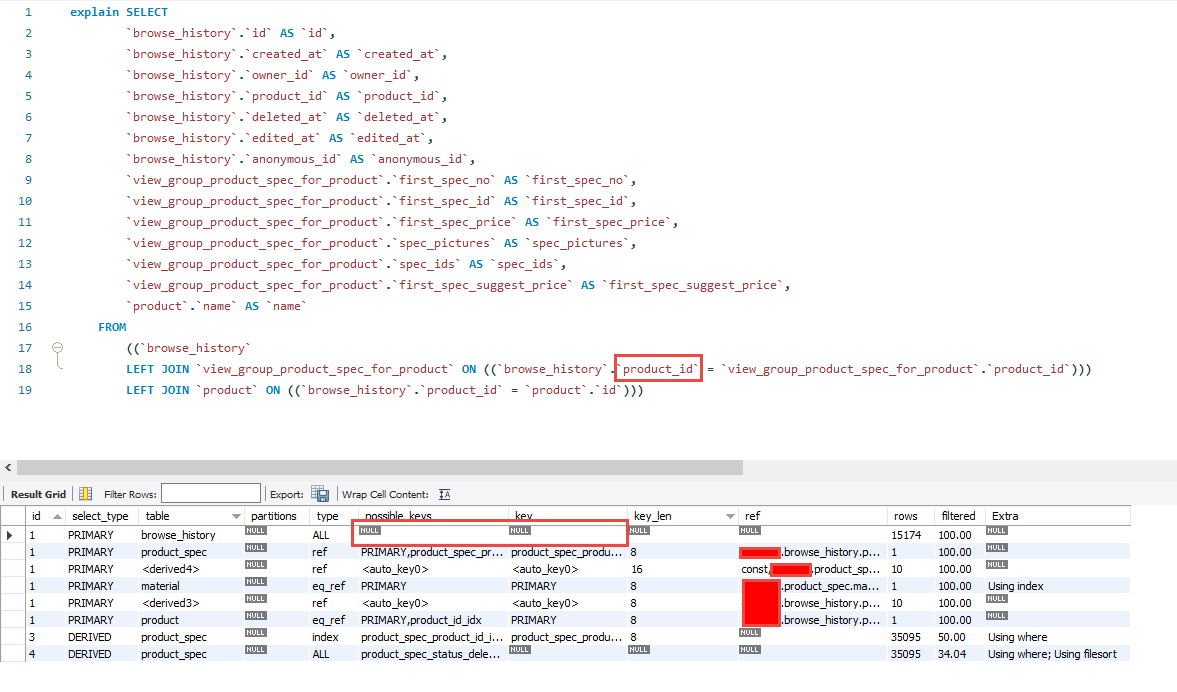
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
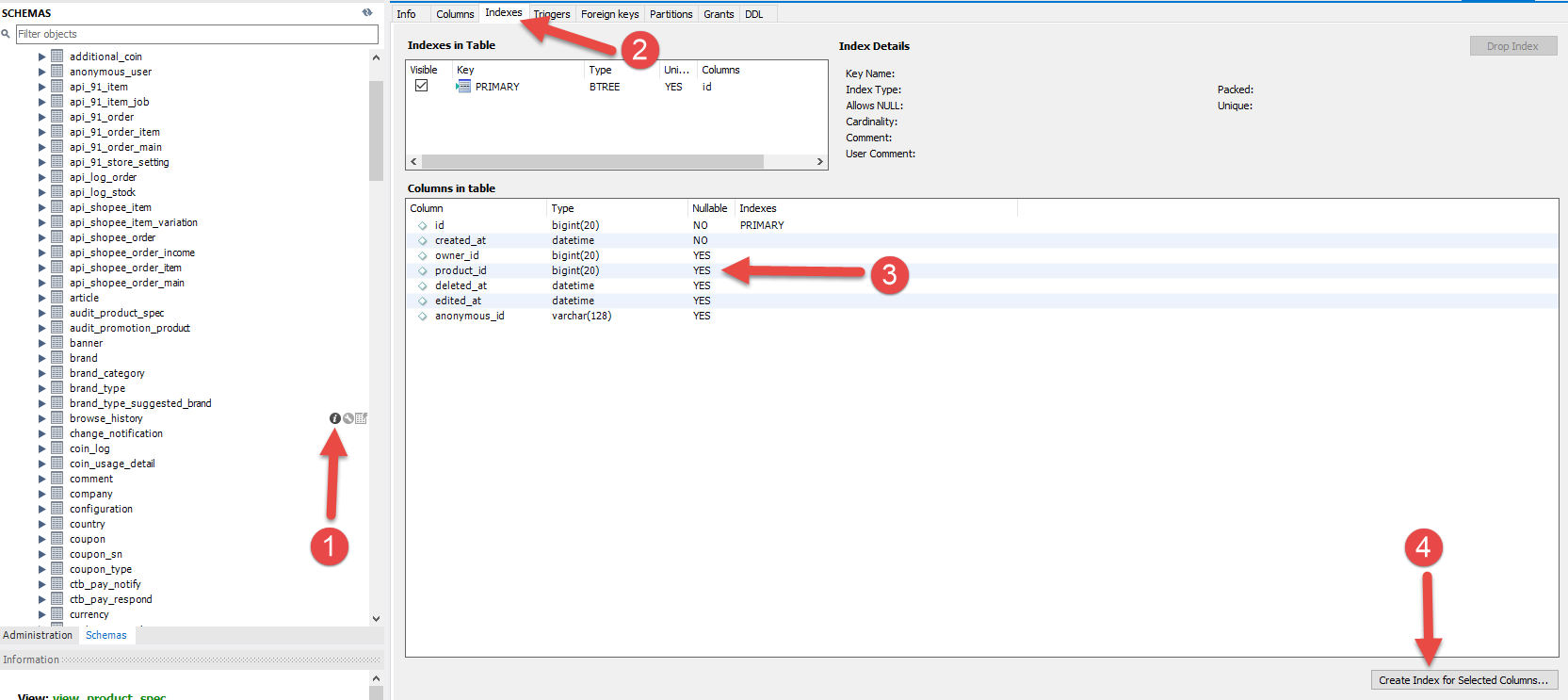
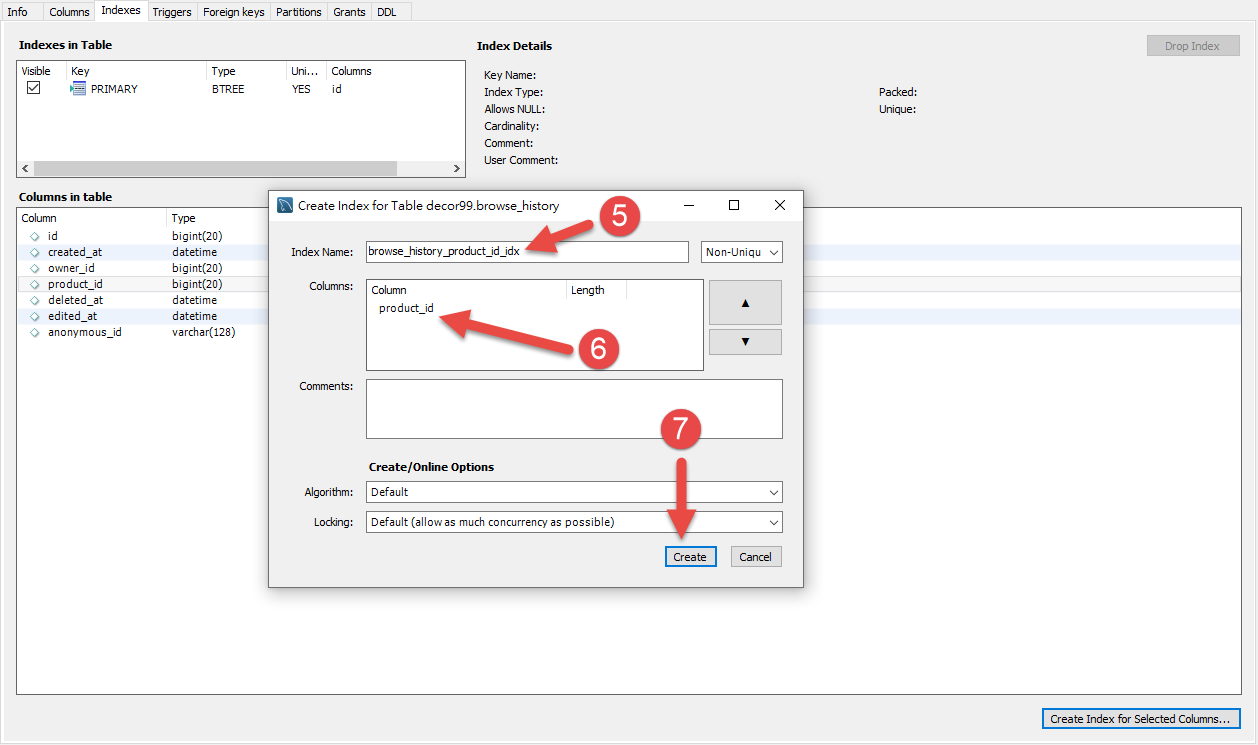
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
梨子, 2022/3/28 下午 09:00:29
若是在某個 namespace 之下, 有和 Root 階層相同名稱的物件. 此時, 該 namespace 之下的物件無法直接指定根目錄下的物件.
解決方法, 在物件名稱前面加上 global::

解決方法, 在物件名稱前面加上 global::
Bike, 2019/1/3 上午 09:47:20
由於工作排程往往有數十個甚至百來個 因此需要一個方法能快速備份及移轉到其他 server 的方法
查了一下,好像也只能這樣做
---- 使用指令把全部排程匯出 ----
參考網址
https://msdn.microsoft.com/en-us/library/windows/desktop/bb736357%28v=vs.85%29.aspx?f=255&MSPPError=-2147217396
schtasks /query /XML > all_tasks.xml
schtasks /query /FO CSV /V >sched_tasks.csv
** xml 比較有用,可以用來匯入到其他server排程,但還要額外處理才能匯入
** csv 只是用來看看目前有哪些排程 可以用來做報表看看
** 這些是全部排程,還要特別處理把 Microsoft 及其他軟體建的排程移除
--------------------------------------------------------------
----如何匯入工作排程到其他 server --------
** 需再寫程式把 all_tasks.xml 拆解成所有排程的單一 xml
並且生成指令 bat
** 注意 xml 必須是 UTF-16 (unicode)
因為 "schtasks /query /XML > all_tasks.xml"產生 xml 是 ansi
參考網址
https://serverfault.com/questions/325569/how-do-i-import-multiple-tasks-from-a-xml-in-windows-server-2008
** /TN "排程名稱" --- 排程名稱可以是路徑名
D:\>schtasks.exe /create /TN "\2016JOB\Global\CountryMonthlyStats" /XML "D:\one_task.xml"
** 下面程式碼只是下面程式碼只是參考 還沒實作過
=====================================
var taskXML = new XmlDocument();
taskXML.Load(@"d:\temp\schedtasksBackup.xml");
var batbody = new StringBuilder();
XmlNodeList tasks = taskXML.DocumentElement.GetElementsByTagName("Task");
string strFileName = "d:\\temp\\Task";
for (int i = 0; i < tasks.Count; i++) {
string onetaskXML = tasks[i].OuterXml;
//Create the New File. With a little more extra effort
//you can get the name from a comment above the task -> 應該把註解裡的名稱抓出
XmlWriter xw = XmlWriter.Create(strFileName + "_" + (i+1) + ".xml");
batbody.AppendLine(string.Format("schtasks.exe /create /TN \"{0}\" /XML \"{1}\"", "Task " + (i+1) + " Name", strFileName + "_" + (i+1) + ".xml"));
//Write the XML
xw.WriteRaw(onetaskXML.ToString());
xw.Close();
// Write a bat to import all the tasks
var batfile = new System.IO.StreamWriter("d:\\temp\\importAllTasks.bat");
batfile.WriteLine(batbody.ToString());
batfile.Close();
}
=====================================
#微軟的排程備份真是有夠爛沒有辦法用介面一鍵搞定
查了一下,好像也只能這樣做
---- 使用指令把全部排程匯出 ----
參考網址
https://msdn.microsoft.com/en-us/library/windows/desktop/bb736357%28v=vs.85%29.aspx?f=255&MSPPError=-2147217396
schtasks /query /XML > all_tasks.xml
schtasks /query /FO CSV /V >sched_tasks.csv
** xml 比較有用,可以用來匯入到其他server排程,但還要額外處理才能匯入
** csv 只是用來看看目前有哪些排程 可以用來做報表看看
** 這些是全部排程,還要特別處理把 Microsoft 及其他軟體建的排程移除
--------------------------------------------------------------
----如何匯入工作排程到其他 server --------
** 需再寫程式把 all_tasks.xml 拆解成所有排程的單一 xml
並且生成指令 bat
** 注意 xml 必須是 UTF-16 (unicode)
因為 "schtasks /query /XML > all_tasks.xml"產生 xml 是 ansi
參考網址
https://serverfault.com/questions/325569/how-do-i-import-multiple-tasks-from-a-xml-in-windows-server-2008
** /TN "排程名稱" --- 排程名稱可以是路徑名
D:\>schtasks.exe /create /TN "\2016JOB\Global\CountryMonthlyStats" /XML "D:\one_task.xml"
** 下面程式碼只是下面程式碼只是參考 還沒實作過
=====================================
var taskXML = new XmlDocument();
taskXML.Load(@"d:\temp\schedtasksBackup.xml");
var batbody = new StringBuilder();
XmlNodeList tasks = taskXML.DocumentElement.GetElementsByTagName("Task");
string strFileName = "d:\\temp\\Task";
for (int i = 0; i < tasks.Count; i++) {
string onetaskXML = tasks[i].OuterXml;
//Create the New File. With a little more extra effort
//you can get the name from a comment above the task -> 應該把註解裡的名稱抓出
XmlWriter xw = XmlWriter.Create(strFileName + "_" + (i+1) + ".xml");
batbody.AppendLine(string.Format("schtasks.exe /create /TN \"{0}\" /XML \"{1}\"", "Task " + (i+1) + " Name", strFileName + "_" + (i+1) + ".xml"));
//Write the XML
xw.WriteRaw(onetaskXML.ToString());
xw.Close();
// Write a bat to import all the tasks
var batfile = new System.IO.StreamWriter("d:\\temp\\importAllTasks.bat");
batfile.WriteLine(batbody.ToString());
batfile.Close();
}
=====================================
#微軟的排程備份真是有夠爛沒有辦法用介面一鍵搞定
darren, 2017/5/5 下午 12:07:30
半夜被老闆 Line,跟我說網頁發生錯誤,他無法看統計報表,會出現作業逾時的錯誤 我查了一下網頁程式,發現是這筆SQL指令跑太久
Select Id, (IsNull(Total, 0) - IsNull(CouponDiscount, 0) + IsNull(CouponAdd, 0)) as Total, Buyer_Email, EN_Packing_List_Status, EN_Order_Source, En_Stock_Status, Create_Date
From V_Order_main With(Nolock)
Where Id in (select Order_Id from Ad_Trace With(NoLock) where (Parameter_Id = 14278))
AND Create_Date >= '2014/10/3' And Create_Date < '2014/10/12'
--> 跑了50秒~ 1分鐘
Select Id, (IsNull(Total, 0) - IsNull(CouponDiscount, 0) + IsNull(CouponAdd, 0)) as Total, Buyer_Email, EN_Packing_List_Status, EN_Order_Source, En_Stock_Status, Create_Date
From V_Order_main With(Nolock)
Where Id in (select Order_Id from Ad_Trace With(NoLock) where (Parameter_Id = 14278))
--> 拿掉日期限制 > 秒殺, 結果跑出 47 筆資料
跑一下執行計畫 原來子查詢的 Ad_Trace 沒有建立Index造成

加上 Index 之後,再跑第一支SQL --> 秒殺
奇怪的地方:
明明訂單日期欄位(Create_Date) 跟 Ad_Trace 沒有多大關係,但是加上日期限制之後,居然會引發 Ad_Trace 搜尋過久的現象
他好像是先依照訂單日期找出所有訂單,然後再從子查詢 Ad_Trace 裡面搜尋有無符合的條件訂單
而不是先跑子查詢找出 Ad_Trace 所有的 Order_Id,再去找符合 Create_Date 的訂單
SQL內部運作的機制真是有點讓人想不透,幸好有評估計畫可以看出問題在哪裡
這讓我想起以前學SQL時的一句話 => 盡量用Join來取代子查詢
使用子查詢真的是效能殺手啊
------繼續補充--------------------------------------
上面的SQL在雙11活動後,由於當日訂單過多,一樣造成SQL timeout 的現象,研判還是子查詢造成的問題
Select Id, (IsNull(Total, 0) - IsNull(CouponDiscount, 0) + IsNull(CouponAdd, 0)) as Total, Buyer_Email, EN_Packing_List_Status, EN_Order_Source, En_Stock_Status, Create_Date
From V_Order_main With(Nolock)
Where Id in (select Order_Id from Ad_Trace With(NoLock) where (Parameter_Id = 14720))
And Create_Date > '2014-11-10' And Create_Date < '2014-11-11'
--> 跑了51秒
所以先將子查詢拿出來跑出一串字串 865828,865890,865901,865903,865928,865955,865990,865993,866005,866035.....
(共1452筆)
再把他拼入sql跑 --> 7秒
darren, 2014/10/11 上午 09:58:18