頁數 1 / 2
下一頁
搜尋 效能 結果:
select id from shopline_customer where id not in (select id from shopline_customer_ext)
以上 SQL 跑不完.
SELECT c.id
FROM shopline_customer c
WHERE NOT EXISTS (
SELECT 1
FROM shopline_customer_ext e
WHERE e.id = c.id
);
以上 SQL 只要 0.3 秒.
GPT 的解釋: (ps, id 是 primary key, 非 null)
🚨 一、為什麼會慢:NOT IN 的效能陷阱
NOT IN 會觸發「反半連接(anti-join)」掃描
PostgreSQL 必須逐筆比對左邊的每個 id
並檢查右邊的 id 是否不在其中
若右邊子查詢結果中出現任何 NULL,NOT IN 的邏輯會「不確定」,導致全表掃描與回退
即使 id 是主鍵(有索引),PostgreSQL 通常仍會展開為 Nested Loop Anti Join 或 Hash Anti Join,
當 shopline_customer 和 shopline_customer_ext 都是大表(例如數十萬筆),
時間就會暴漲。
⚠️ NOT IN + NULL 問題:
即使 id 欄位宣告為 NOT NULL,也可能因外層的隱含條件造成額外檢查負擔。
PostgreSQL 會多執行一次 Anti-Join NULL Filter,浪費時間。
以上 SQL 跑不完.
SELECT c.id
FROM shopline_customer c
WHERE NOT EXISTS (
SELECT 1
FROM shopline_customer_ext e
WHERE e.id = c.id
);
以上 SQL 只要 0.3 秒.
GPT 的解釋: (ps, id 是 primary key, 非 null)
🚨 一、為什麼會慢:NOT IN 的效能陷阱
NOT IN 會觸發「反半連接(anti-join)」掃描
PostgreSQL 必須逐筆比對左邊的每個 id
並檢查右邊的 id 是否不在其中
若右邊子查詢結果中出現任何 NULL,NOT IN 的邏輯會「不確定」,導致全表掃描與回退
即使 id 是主鍵(有索引),PostgreSQL 通常仍會展開為 Nested Loop Anti Join 或 Hash Anti Join,
當 shopline_customer 和 shopline_customer_ext 都是大表(例如數十萬筆),
時間就會暴漲。
⚠️ NOT IN + NULL 問題:
即使 id 欄位宣告為 NOT NULL,也可能因外層的隱含條件造成額外檢查負擔。
PostgreSQL 會多執行一次 Anti-Join NULL Filter,浪費時間。
Bike, 2025/10/29 上午 10:24:11
其實這是老問題了,就是IIS每過29小時會重啟 App Pool 機制
這個機制目的是讓主機可以回收記憶體以增進網站效能,過程是smooth的
當此回收機制開始時,新的request會由新的程序跑,舊的request仍會把他跑完(理論上,但太久的程式還是會自動停)
這樣的機制,最明顯的是會造成 inProc 的 session or cache 資料消失
造成程式上的錯誤,或是user的資料消失
另外,這個29小時回收機制,不會因為程式更新,網站重啟,而重新計算
原本以為這機制影響不大,但最近因為電商後台程式有個排程跑太久剛好被回收機制中斷
然後自己假日在外無法即時處理問題,造成電商客戶在等著把問題解決
想說還是把這個 29小時魔咒 處理一下
在某個特定無排程時間,執行重啟網站
這個機制目的是讓主機可以回收記憶體以增進網站效能,過程是smooth的
當此回收機制開始時,新的request會由新的程序跑,舊的request仍會把他跑完(理論上,但太久的程式還是會自動停)
這樣的機制,最明顯的是會造成 inProc 的 session or cache 資料消失
造成程式上的錯誤,或是user的資料消失
另外,這個29小時回收機制,不會因為程式更新,網站重啟,而重新計算
原本以為這機制影響不大,但最近因為電商後台程式有個排程跑太久剛好被回收機制中斷
然後自己假日在外無法即時處理問題,造成電商客戶在等著把問題解決
想說還是把這個 29小時魔咒 處理一下
在某個特定無排程時間,執行重啟網站
darren, 2025/9/1 上午 10:30:33
改寫成可輸入多參數,效能也比較好的版本。
以下為測試碼,請自行依照專案需求做修改。
以下為測試碼,請自行依照專案需求做修改。
var root = "C://wdqd/qwewq";
var addPath = @"//\\/fwef/qwf";
var addPath2 = @"5fwfef/qwf";
var addPath3 = @"//fwef/qwf";
var addPath4 = @"\\\fwef/qwf";
var addPath5 = @"\\\\\/fwef/qwf";
var result = root.AddPath(addPath, addPath2, addPath3, addPath4, addPath5);
Console.WriteLine(result);
public static class Helper
{
public static string AddPath(this string value, params string[] addPaths)
{
if (string.IsNullOrEmpty(value))
{
throw new Exception("起始目錄不可以為空字串");
}
if (value.Contains("..") || addPaths.Any(x => x.Contains("..")))
{
throw new Exception($"value: {value}, addPaths: {addPaths.Where(x => x.Contains("..")).ToOneString()} 檔名與路徑不可包含 ..");
}
var paths = addPaths.Select(x => x.Substring(x.FindLastContinuousCharPosition('/', '\\') + 1).SafeFilename()).ToList();
if (paths.Any(x => System.IO.Path.IsPathRooted(x)))
{
throw new Exception("不可併入完整路徑 ..");
}
paths.Insert(0, value.SafeFilename());
return System.IO.Path.Combine(paths.ToArray());
}
public static string ToOneString<T>(this IEnumerable<T> list, string separator = ",")
{
var strList = list.Select(x => x.ToString());
return string.Join(separator, strList);
}
public static int FindLastContinuousCharPosition(this string input, params char[] targets)
{
int lastPosition = -1;
for (int i = 0; i < input.Length; i++)
{
if (targets.Contains(input[i]))
{
lastPosition = i;
}
else
{
break;
}
}
return lastPosition;
}
public static string SafeFilename(this string value)
{
return GetValidFilename(value);
}
public static string GetValidFilename(string value)
{
string ValidFilenameCharacters = @"0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ\-_$.@:/# ";
if (value.Contains(".."))
{
throw new Exception("路徑中不可包含 .. ");
}
string newUrl = "";
for (int i = 0; i < value.Length; i++)
{
var c = value.Substring(i, 1);
int k = ValidFilenameCharacters.IndexOf(c);
if (k < 0)
{
throw new Exception($"檔名 '{value}' 中有非法的字元 '" + c + "'。");
}
newUrl += ValidFilenameCharacters.Substring(k, 1);
}
return newUrl;
}
}
梨子, 2023/8/28 上午 09:43:49
發現了一個很新奇的東西 Parallel
他可以做到平行處理迭代這件事
只要迴圈邏輯上不需要有先後順序的情況就可以使用來大幅度提高效能!

輸出值

需要特別注意如果於非同步中使用lock應使用SemaphoreSlim
如果要使用Dictionay應使用ConcurrentDictionary
他可以做到平行處理迭代這件事
只要迴圈邏輯上不需要有先後順序的情況就可以使用來大幅度提高效能!
輸出值
需要特別注意如果於非同步中使用lock應使用SemaphoreSlim
如果要使用Dictionay應使用ConcurrentDictionary
梨子, 2023/4/11 下午 12:49:47
上一集當中我們完成了Lucene基本操作中的Create與Read,這一集會將CRUD中的Update與Delete的操作方法告訴你,並且本集會著重於講解關於"Norms"與權重(Boost)在Lucene中的運作概念。
首先我們建立一個.Net 6的主控台應用程式
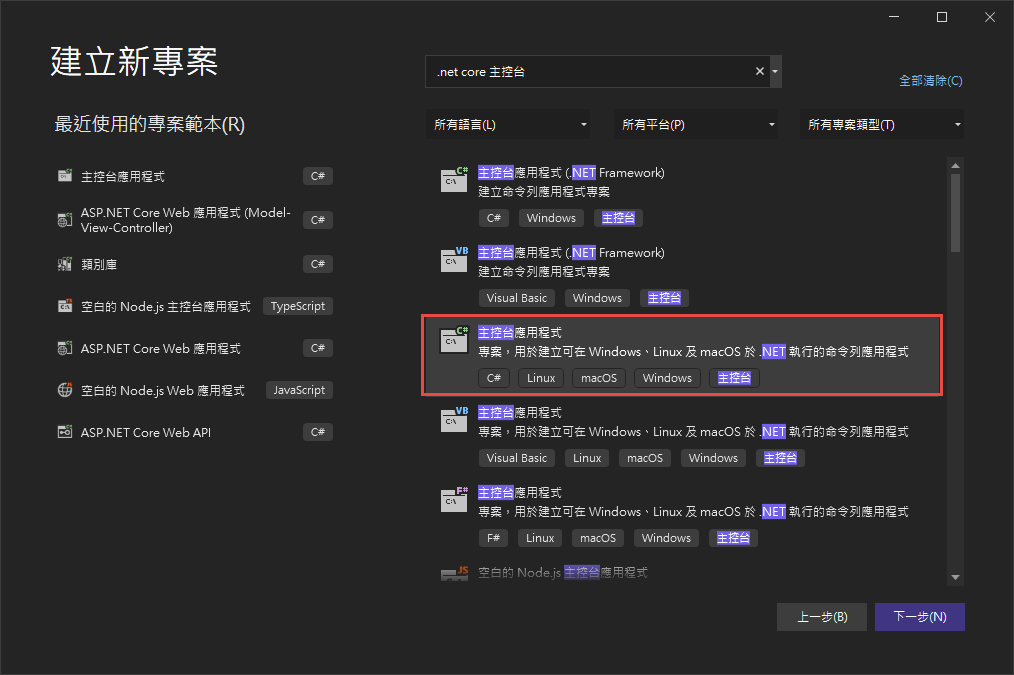
建立好後於右側專案右鍵選擇"管理Nuget套件",並選擇"瀏覽">於搜索列中搜尋"Lucene">安裝3.0.3最新穩定版 與 "System.Configuration.ConfigurationManager"
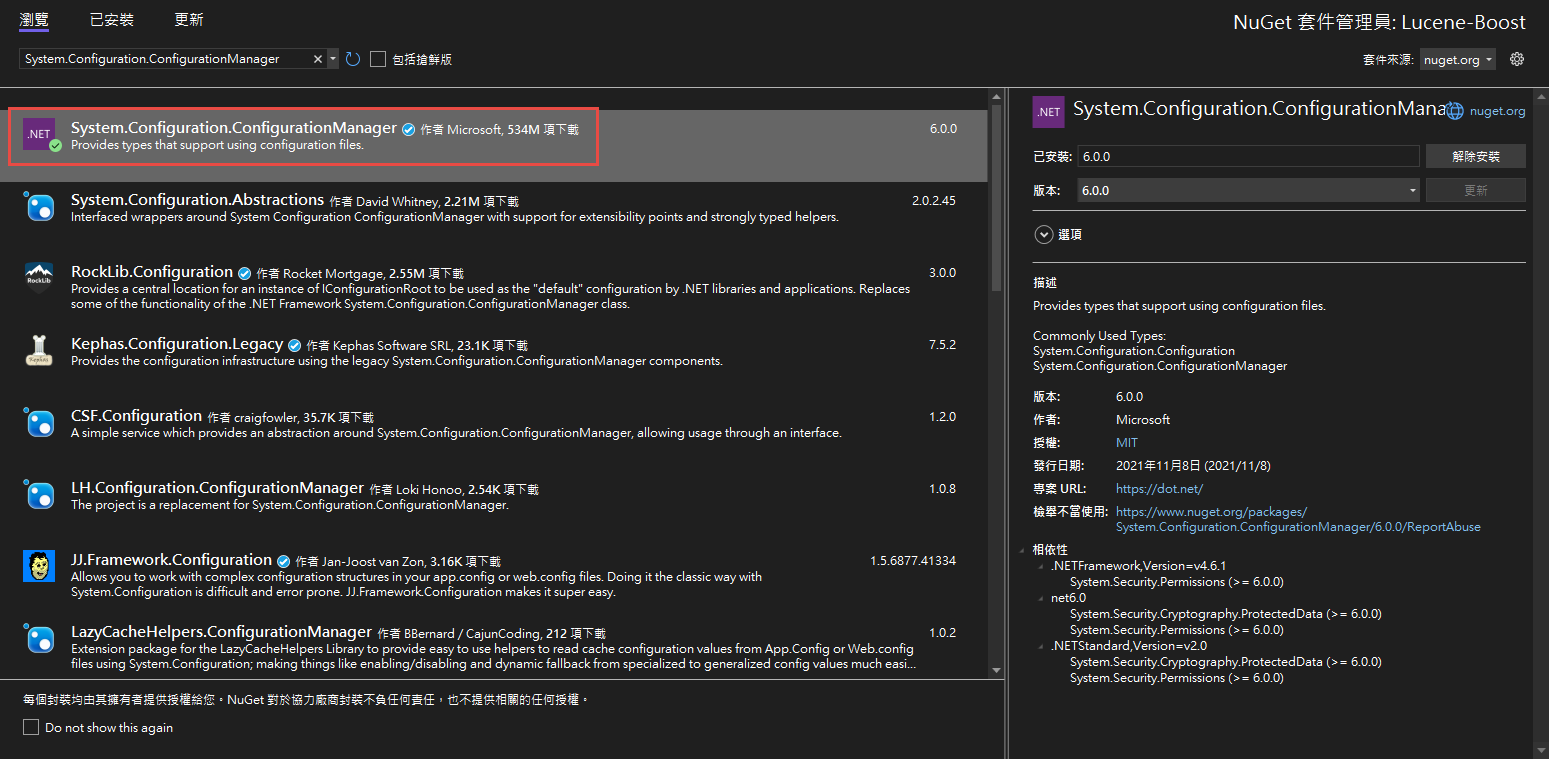
安裝好後就可以於專案內使用Lucene套件囉!
再來依照上一篇的教學建立一套簡單的Lucene查詢
好囉! 接下來我們要如何更新索引呢?
更新其實就是將存在的索引刪除並重新建立Document,不存在的則直接新增。
首先準備一組資料準備更新
*欲更新的Document必須與創建所引時使用的Document欄位相同*
來測試看看
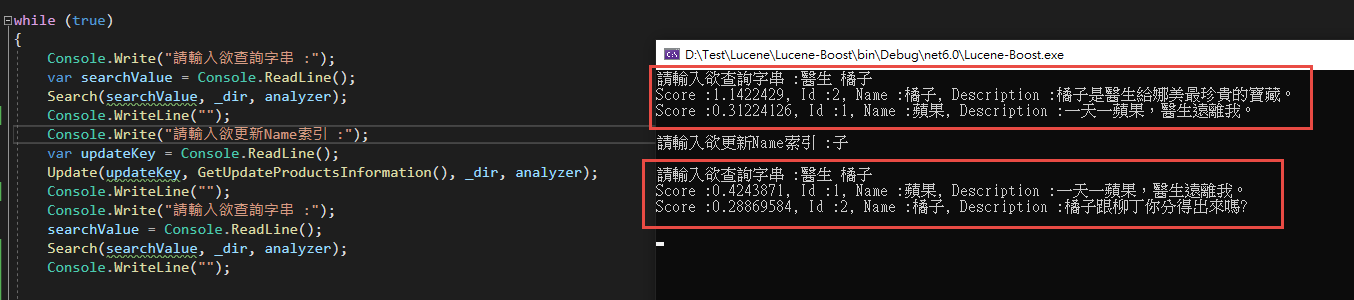
可以看見 Name = 橘子 的索引已經改為我們新準備的資料囉。
再來是刪除!
與更新非常相似,只需要使用deleteDocument()就可以了。
再來看看輸出結果
可以發現 Score :0.7554128, Id :2, Name :橘子, Description :醫生給娜美最珍貴的寶藏。這筆索引已經被移除囉!
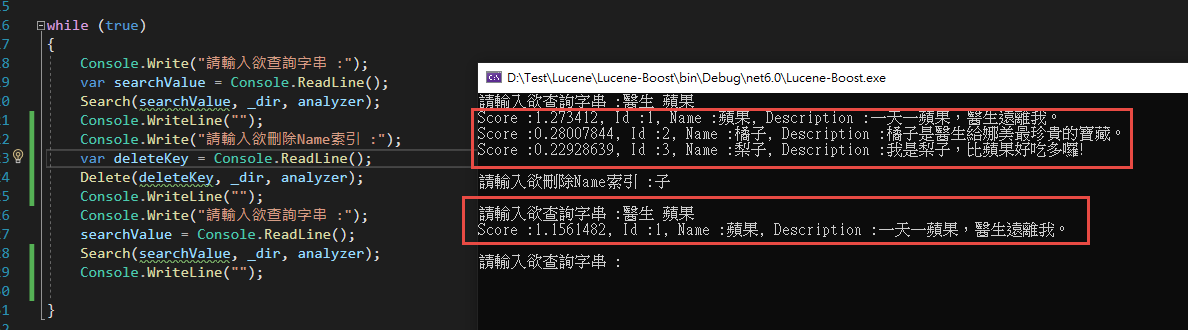
可以發現筆者於更新或刪除時都是輸入單一字來做異動,除了表達可以對索引做複合更動外,
是因為更新與刪除索引同樣會使用到分詞器(analyzer),
*所輸入的索引值非ID等數值時必須要配合分詞器的分詞能力*才能取得所想異動的索引喔!
Boost是什麼呢?
Boost 分為 :
1. Index Time Boost : 在建立索引時就計算好的值。例如上一篇中提到的(NORMS)
2. Query Time Boost : 查詢時賦與搜尋條件不同的值以影響結果。
我們先來測試Index Time Boost的部分
並記得重新CreateIndex才能刷新欄位的權重值喔。
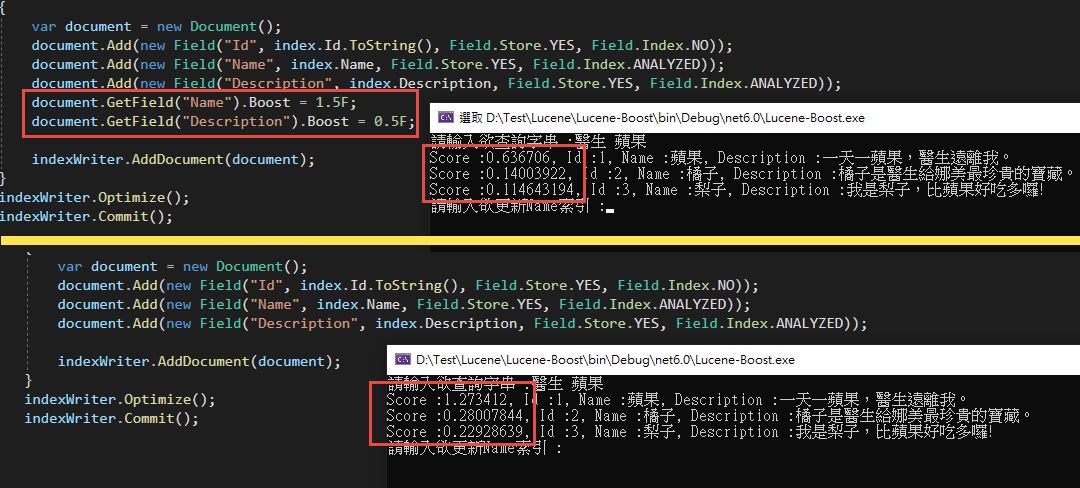
很明顯的搜尋出來的Score分數變動了! 但是有沒有發現明明Name欄位的Boost改成了1.5,蘋果的數值卻仍然只有一半呢?
這是因為我們的Search中所參照的欄位為Description,所以在計算Score的時候其實是完全沒有參與的喔!
另外要記得,使用Index Time Boost的時候,欲給予銓重分配的欄位Field.Index不能使用NO_NORMS,不然這個欄位並不會紀錄權重的資料。
再來我們試試看Query Time Boost
這次我們搜尋兩個欄位"Name"與"Description",並使用 BooleanQuery來將其組合。
BooleanQuery中的 Occur有三種參數 : "MUST","MUST_NOT","SHOULD",功能與字面上的意思一樣為"必須要有","必須沒有"與"有無都包含"。

查詢出來的分數就不一樣囉!
以上就是這一次的分享,Lucene是一款容易入門但是要實際上戰場卻又十分複雜的功能,想要達成真正高效能的全文檢索,在前期的文件規畫配置與資料的權重配比都是一個巨大的挑戰。未來會繼續分享關於Lucene的其他有趣功能,還請繼續期待呦!
另外也可以到GitHub下載我的範例來參考呦!
GitHub: https://github.com/g13579112000/Lucene
參考文件:
1. 黑暗大大的全文檢索筆記 : https://blog.darkthread.net/blog/lucene-net-notes-1/
2. Makble : http://makble.com/lucene-field-boost-example
3. CSDN Jack2013tong 文章 : https://blog.csdn.net/huwei2003/article/details/53408388
首先我們建立一個.Net 6的主控台應用程式
建立好後於右側專案右鍵選擇"管理Nuget套件",並選擇"瀏覽">於搜索列中搜尋"Lucene">安裝3.0.3最新穩定版 與 "System.Configuration.ConfigurationManager"
安裝好後就可以於專案內使用Lucene套件囉!
再來依照上一篇的教學建立一套簡單的Lucene查詢
using Lucene.Net.Analysis.Standard;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.QueryParsers;
using Lucene.Net.Search;
using Lucene.Net.Store;
var _dir = new DirectoryInfo("LuceneDocument");
if (!File.Exists(_dir.FullName))
{
System.IO.Directory.CreateDirectory(_dir.FullName);
}
var analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_CURRENT);
CreateIndex(GetProductsInformation(), _dir, analyzer);
while (true)
{
Console.Write("請輸入欲查詢字串 :");
var searchValue = Console.ReadLine();
Search(searchValue, _dir, analyzer);
}
void CreateIndex(List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
void Search(string searchValue, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(_dir))
{
var parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
using (var indexSearcher = new IndexSearcher(directory))
{
var queryLimit = 20;
var hits = indexSearcher.Search(parser, queryLimit);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
}
}
}
List<Product> GetProductsInformation()
{
return new List<Product> {
new Product{ Id = 1, Name = "蘋果", Description = "一天一蘋果,醫生遠離我。"},
new Product{ Id = 2, Name = "橘子", Description = "醫生給娜美最珍貴的寶藏。"},
new Product{ Id = 3, Name = "梨子", Description = "我是梨子,比蘋果好吃多囉!"},
new Product{ Id = 4, Name = "葡萄", Description = "吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮"},
new Product{ Id = 5, Name = "榴槤", Description = "水果界的珍寶!好吃一直吃。"}
};
}
class Product
{
public long Id { get; set; }
public string Name { get; set; } = null!;
public string Description { get; set; } = null!;
}
好囉! 接下來我們要如何更新索引呢?
更新其實就是將存在的索引刪除並重新建立Document,不存在的則直接新增。
首先準備一組資料準備更新
List<Product> GetUpdateProductsInformation()
{
return new List<Product>
{
new Product{ Id = 6, Name = "香蕉", Description = "運動完後吃根香蕉補充養分。"},
new Product{ Id = 2, Name = "橘子", Description = "橘子跟柳丁你分得出來嗎?"}
};
}
*欲更新的Document必須與創建所引時使用的Document欄位相同*
void Update(string key, List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using( var directory = FSDirectory.Open(dir))
{
using(var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
indexWriter.UpdateDocument(new Term("Name", key) ,document);
}
}
}
}
來測試看看
可以看見 Name = 橘子 的索引已經改為我們新準備的資料囉。
再來是刪除!
與更新非常相似,只需要使用deleteDocument()就可以了。
void Delete(string key, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
indexWriter.DeleteDocuments(new Term("Name", key));
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
再來看看輸出結果
可以發現 Score :0.7554128, Id :2, Name :橘子, Description :醫生給娜美最珍貴的寶藏。這筆索引已經被移除囉!
可以發現筆者於更新或刪除時都是輸入單一字來做異動,除了表達可以對索引做複合更動外,
是因為更新與刪除索引同樣會使用到分詞器(analyzer),
*所輸入的索引值非ID等數值時必須要配合分詞器的分詞能力*才能取得所想異動的索引喔!
Boost是什麼呢?
Boost 分為 :
1. Index Time Boost : 在建立索引時就計算好的值。例如上一篇中提到的(NORMS)
2. Query Time Boost : 查詢時賦與搜尋條件不同的值以影響結果。
我們先來測試Index Time Boost的部分
void CreateIndexWithBoost(List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
document.GetField("Name").Boost = 1.5F;
document.GetField("Description").Boost = 0.5F;
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
並記得重新CreateIndex才能刷新欄位的權重值喔。
很明顯的搜尋出來的Score分數變動了! 但是有沒有發現明明Name欄位的Boost改成了1.5,蘋果的數值卻仍然只有一半呢?
這是因為我們的Search中所參照的欄位為Description,所以在計算Score的時候其實是完全沒有參與的喔!
另外要記得,使用Index Time Boost的時候,欲給予銓重分配的欄位Field.Index不能使用NO_NORMS,不然這個欄位並不會紀錄權重的資料。
再來我們試試看Query Time Boost
void SearchWithBoost(string searchValue, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(_dir))
{
using (var indexSearcher = new IndexSearcher(directory))
{
var query = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Name", analyzer).Parse(searchValue);
var query2 = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
query.Boost = 2.0F;
query2.Boost = 0.5F;
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.Add(query, Occur.SHOULD);
booleanQuery.Add(query2, Occur.SHOULD);
var hits = indexSearcher.Search(booleanQuery, 20);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
}
}
}
這次我們搜尋兩個欄位"Name"與"Description",並使用 BooleanQuery來將其組合。
BooleanQuery中的 Occur有三種參數 : "MUST","MUST_NOT","SHOULD",功能與字面上的意思一樣為"必須要有","必須沒有"與"有無都包含"。
查詢出來的分數就不一樣囉!
以上就是這一次的分享,Lucene是一款容易入門但是要實際上戰場卻又十分複雜的功能,想要達成真正高效能的全文檢索,在前期的文件規畫配置與資料的權重配比都是一個巨大的挑戰。未來會繼續分享關於Lucene的其他有趣功能,還請繼續期待呦!
另外也可以到GitHub下載我的範例來參考呦!
GitHub: https://github.com/g13579112000/Lucene
參考文件:
1. 黑暗大大的全文檢索筆記 : https://blog.darkthread.net/blog/lucene-net-notes-1/
2. Makble : http://makble.com/lucene-field-boost-example
3. CSDN Jack2013tong 文章 : https://blog.csdn.net/huwei2003/article/details/53408388
梨子, 2022/4/20 下午 09:34:03
首先尋找出一支欲調效的Table或Query
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
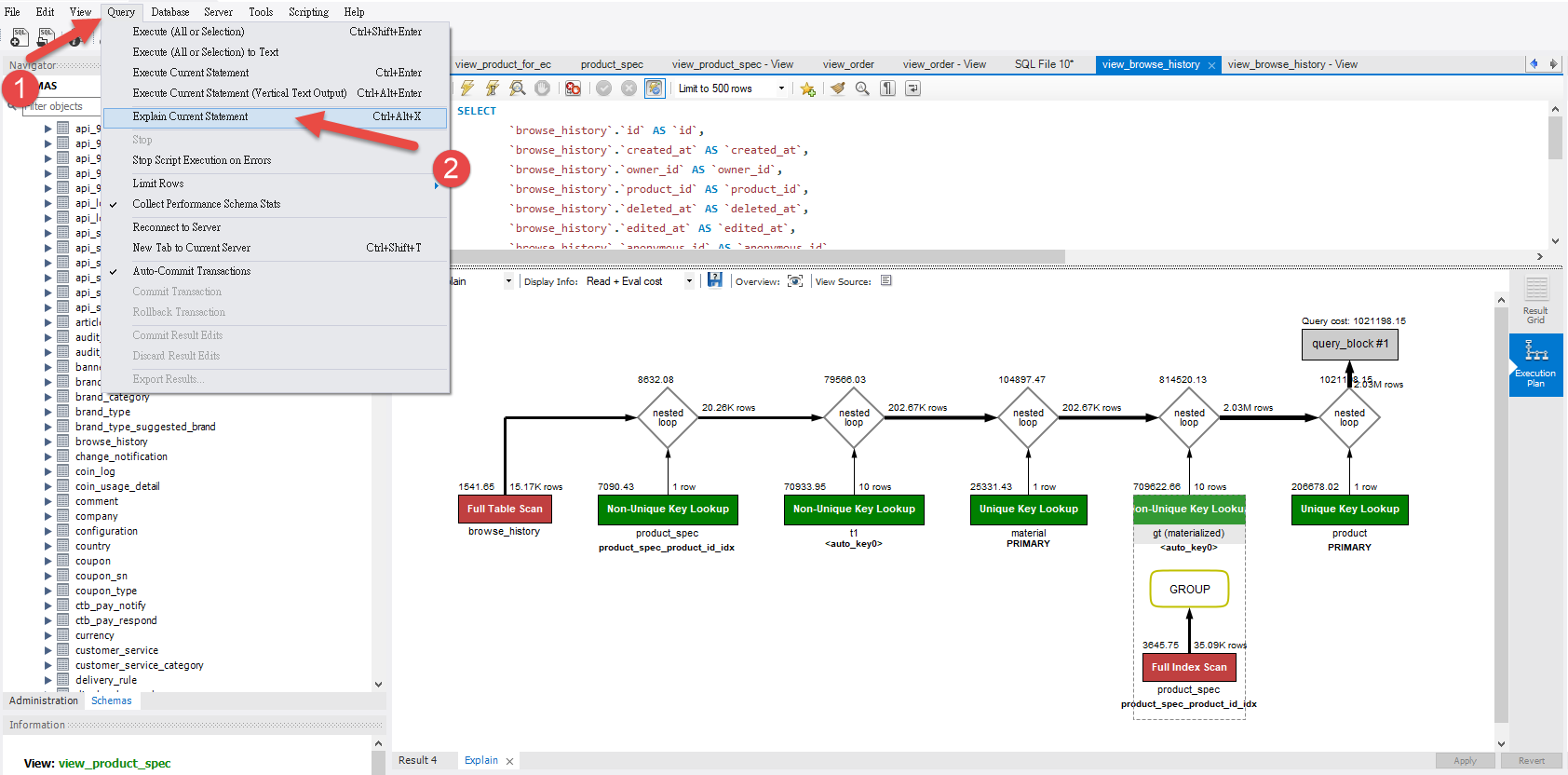
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
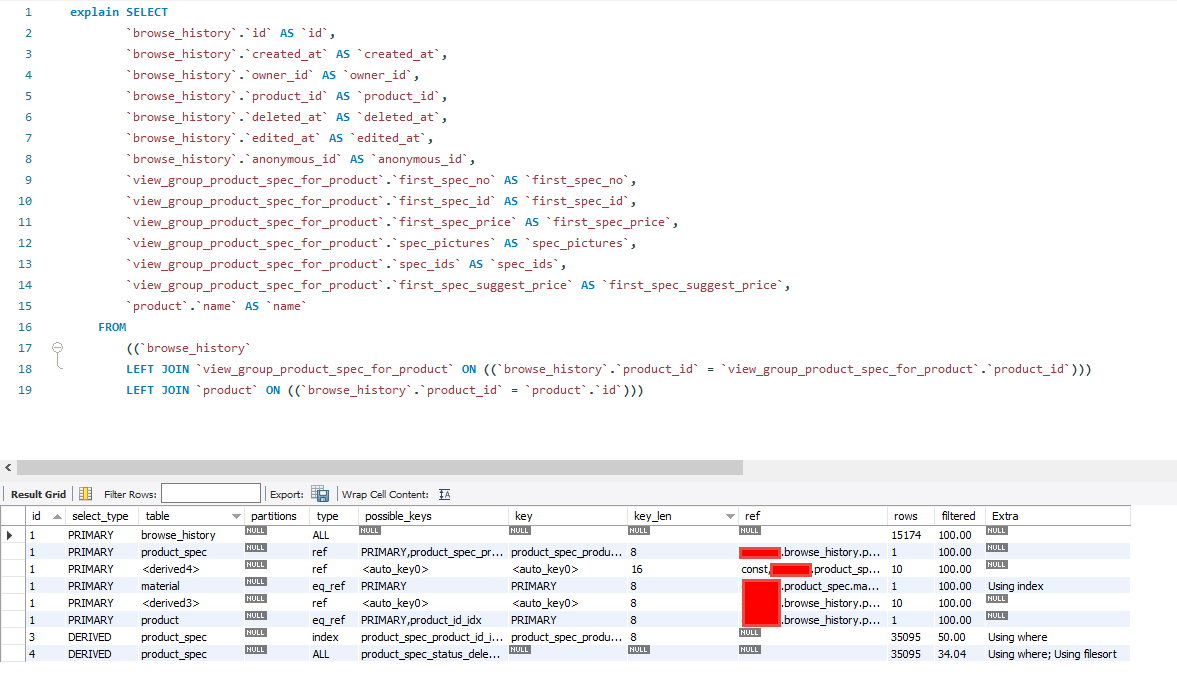
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
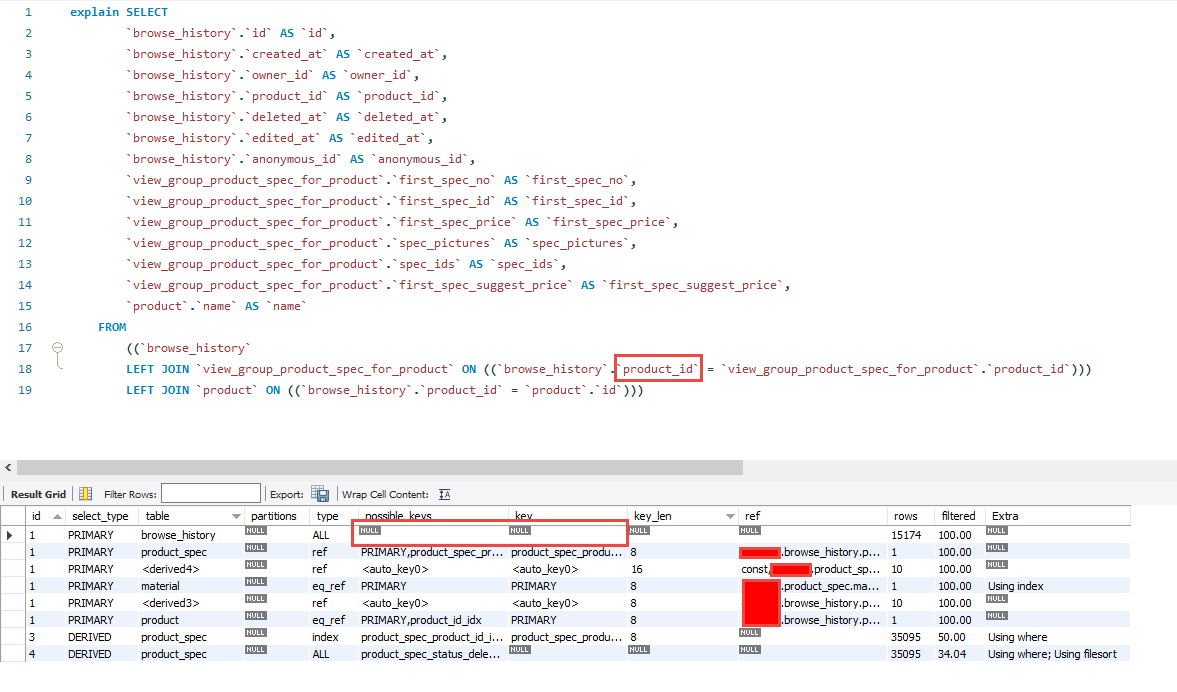
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
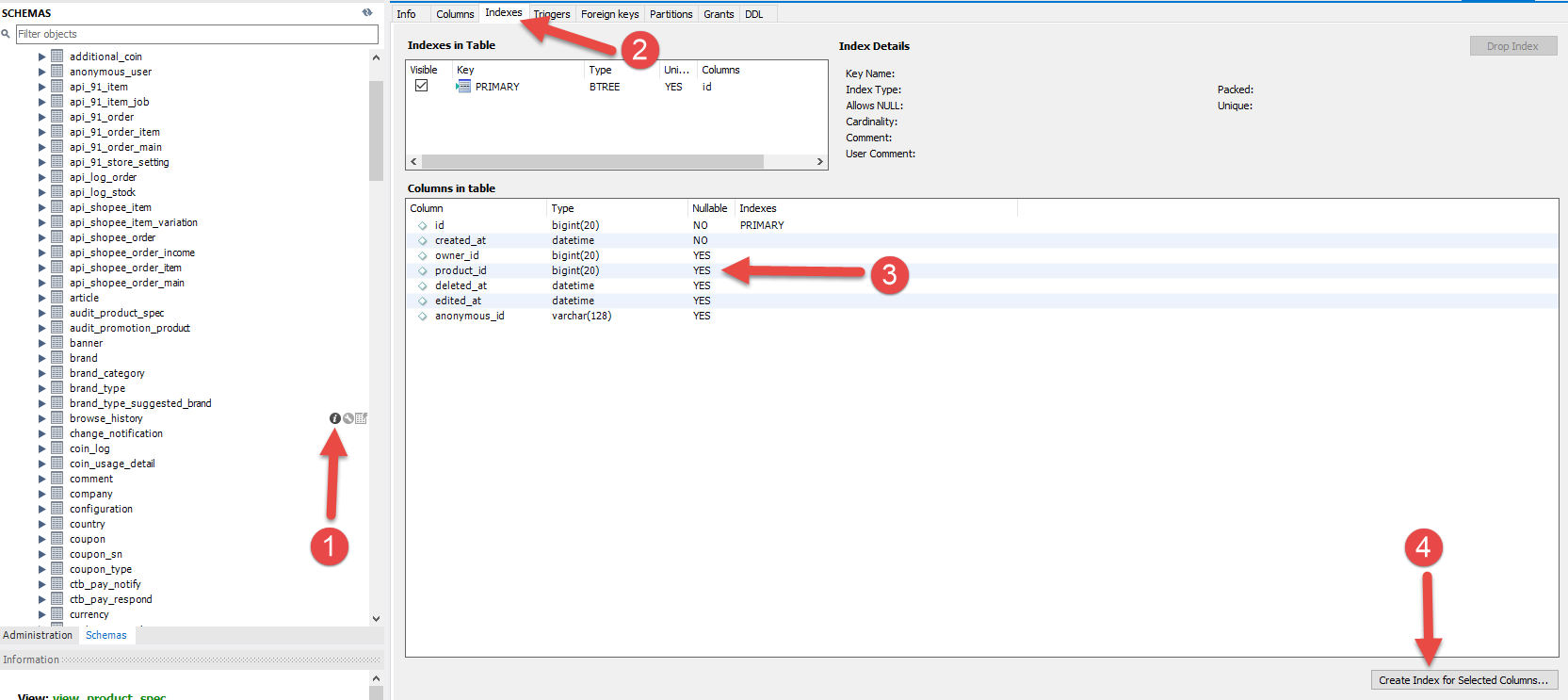
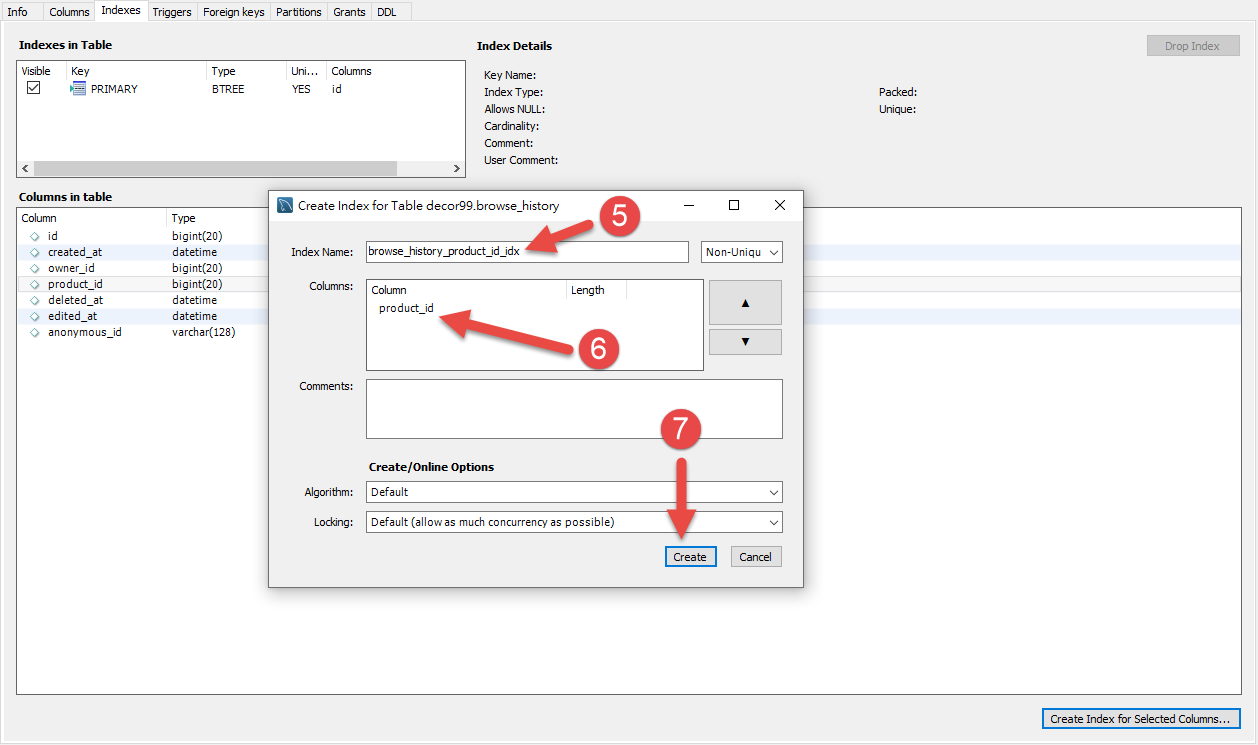
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
梨子, 2022/3/28 下午 09:00:29
Lucene.Net是一套C#開源全文索引庫,其主要包含了:
· Index : 提供索引的管理與詞組的排序
· Search : 提供查詢相關功能
· Store : 支援資料儲存管理,包括I/O操作
· Util : 共用套件
· Documents : 負責描述索引儲存時的文件結構管理
· QueryParsers : 提供查詢語法
· Analysis : 負責分析內容
要達到高效能的全文檢索讓機器可以明白我們的語言,最重要的關鍵就是"分詞器"了。
試想一下這一句話你會如何拆分成一段一段的關鍵字呢?
"一天一蘋果,醫生遠離我"
還有英文版本
"An apple a day, doctor keep me away."
中文版本的拆分:
"一天"、"一"、"蘋果"、"醫生"、"遠離"、"我"
英文版本的拆分:
"apple"、"day"、"doctor"、"keep"、"me"、"away"
有沒有注意到不同語系所分析出來的關鍵字有一點不一樣呢?
而在Lucene中分詞的工作會交給Analysis來完成,
不過我們可以依照不同的語系去選擇想使用的分詞器(Analyzer)!
首先簡單說明一下Lucene的實作流程
1. 確認主要搜尋的語系來決定使用的分詞器(analyzer)
2. 建立Document依照analyzer匯入資料
(前置完成)
3. 建立IndexSearcher導入準備好的Document
4. 建立Parser來分析SearchValue
5. 使用IndexSearcher分析Parser取得結果(Hits)
*本專案使用的是Lucene.Net 3.0.3*
接下來我們來建立一個提供查詢使用的Document。
如此一來我們就建立好Lucene的基本配備囉!
其中analyzer的部分我們使用Lucene.Net預設,
要特別注意的是,其處理中文語系的能力非常之爛!
之後再寫一篇文章深入探討。
再來值得一提的是
前兩個參數就是Key跟Value,可以簡單理解為欄位與其內容。
後面兩個參數是重點!
Store: 代表是否儲存這個Key的Value
例如在google打上台南美食會搜索出許多不同的文章連結,
不過google給你的資料中最重要的不是文章內容(Description),
而是哪一篇文章(Name)與台南美食最有關係。
假如今天我只要回傳一個列表而不用提示文章中有哪些內容,
那麼我就可以選擇給"Description" Field.Store.No來節省空間。
Index:
· NO - 不加入索引,這個內容只需要隨著結果出爐,不需要在查詢的時候被考慮。
· ANALYZED、NOT_ANALYZED - 是否使用分詞
· NO_NORMS - 關閉權重功能
或許許多人會對權重功能(NORMS)感到疑惑,
簡單的舉個例子
{ Id=1, Key="蘋果", Value="一天一蘋果,醫生遠離我。"}
{ Id=2, Key="橘子", Value="醫生給娜美最珍貴的寶藏。"}
{ Id=3, Key="梨子", Value="我是梨子,比蘋果蘋果好吃多囉!"}
當我搜尋"蘋果"的時候結果會是
{ Id=1, MatchKey=1, MatchValue=1, Score=(1*5) + (1*2) = 7}
{ Id=3, MatchKey=0, MatchValue=1, Score=(0*5) + (2*2) = 4}
有發現了嗎?
雖然同樣都對中兩個結果但是Id 1的資料Key值中有包含關鍵字,
因此得到較高的分數排在Id 3前方
準備好Document了,我們可以開始來實際使用看看囉!
最後的結果(Hits),是需要再回到Document去撈出對應的資料喔!
是不是非常簡單呢?
筆者寫了一個簡單的範例在GitHub上,秉持著追求新技術的心使用了.Net 6,還請各位大大多多包涵。
有中英文兩種Repository,只需要在上方的DI注入切換就可以囉!
GitHub連結: https://github.com/g13579112000/Lucene
筆者第一次撰寫這種教學文章,有哪邊錯誤的非常歡迎一起來討論指教。
之後有機會再撰寫Lucene更深入的應用方面,
例如權重的分配與分詞器的選擇與使用。
感謝您的閱讀。
參考文獻:
1.黑暗大大的全文檢索筆記: https://blog.darkthread.net/blog/lucene-net-notes-1/
2.使用.Net實現全文檢索: https://blog.csdn.net/huwei2003/article/details/53408388
3.伊凡的部落格: http://irfen.me/5-lucene4-9-learning-record-lucene-analysis-tokenizer/
4.純淨天空代碼範例: https://vimsky.com/zh-tw/examples/detail/csharp-ex-Lucene.Net.Documents-Document---class.html
· Index : 提供索引的管理與詞組的排序
· Search : 提供查詢相關功能
· Store : 支援資料儲存管理,包括I/O操作
· Util : 共用套件
· Documents : 負責描述索引儲存時的文件結構管理
· QueryParsers : 提供查詢語法
· Analysis : 負責分析內容
要達到高效能的全文檢索讓機器可以明白我們的語言,最重要的關鍵就是"分詞器"了。
試想一下這一句話你會如何拆分成一段一段的關鍵字呢?
"一天一蘋果,醫生遠離我"
還有英文版本
"An apple a day, doctor keep me away."
中文版本的拆分:
"一天"、"一"、"蘋果"、"醫生"、"遠離"、"我"
英文版本的拆分:
"apple"、"day"、"doctor"、"keep"、"me"、"away"
有沒有注意到不同語系所分析出來的關鍵字有一點不一樣呢?
而在Lucene中分詞的工作會交給Analysis來完成,
不過我們可以依照不同的語系去選擇想使用的分詞器(Analyzer)!
首先簡單說明一下Lucene的實作流程
1. 確認主要搜尋的語系來決定使用的分詞器(analyzer)
2. 建立Document依照analyzer匯入資料
(前置完成)
3. 建立IndexSearcher導入準備好的Document
4. 建立Parser來分析SearchValue
5. 使用IndexSearcher分析Parser取得結果(Hits)
*本專案使用的是Lucene.Net 3.0.3*
接下來我們來建立一個提供查詢使用的Document。
// 取得或建立Lucene文件資料夾
if (!File.Exists(_dir.FullName))
{
System.IO.Directory.CreateDirectory(_dir.FullName);
}
// Asp.Net Core需要於Nuget安裝System.Configuration.ConfigurationManager提供用戶端應用程式的組態檔存取
Lucene.Net.Store.Directory directory = FSDirectory.Open(_dir);
// 選擇分詞器
var analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_CURRENT);
// 資料來源
var repository = new Repository();
// 依照指定的文件結構來建立
var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);
foreach (var index in repository)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.NO, Field.Index.ANALYZED));
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
indexWriter.Dispose();
如此一來我們就建立好Lucene的基本配備囉!
其中analyzer的部分我們使用Lucene.Net預設,
要特別注意的是,其處理中文語系的能力非常之爛!
之後再寫一篇文章深入探討。
再來值得一提的是
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));前兩個參數就是Key跟Value,可以簡單理解為欄位與其內容。
後面兩個參數是重點!
Store: 代表是否儲存這個Key的Value
例如在google打上台南美食會搜索出許多不同的文章連結,
不過google給你的資料中最重要的不是文章內容(Description),
而是哪一篇文章(Name)與台南美食最有關係。
假如今天我只要回傳一個列表而不用提示文章中有哪些內容,
那麼我就可以選擇給"Description" Field.Store.No來節省空間。
Index:
· NO - 不加入索引,這個內容只需要隨著結果出爐,不需要在查詢的時候被考慮。
· ANALYZED、NOT_ANALYZED - 是否使用分詞
· NO_NORMS - 關閉權重功能
或許許多人會對權重功能(NORMS)感到疑惑,
簡單的舉個例子
{ Id=1, Key="蘋果", Value="一天一蘋果,醫生遠離我。"}
{ Id=2, Key="橘子", Value="醫生給娜美最珍貴的寶藏。"}
{ Id=3, Key="梨子", Value="我是梨子,比蘋果蘋果好吃多囉!"}
當我搜尋"蘋果"的時候結果會是
{ Id=1, MatchKey=1, MatchValue=1, Score=(1*5) + (1*2) = 7}
{ Id=3, MatchKey=0, MatchValue=1, Score=(0*5) + (2*2) = 4}
有發現了嗎?
雖然同樣都對中兩個結果但是Id 1的資料Key值中有包含關鍵字,
因此得到較高的分數排在Id 3前方
準備好Document了,我們可以開始來實際使用看看囉!
// 決定所要搜索的欄位
var parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
// 提供剛剛建立的Document
var indexSearcher = new IndexSearcher(directory);
// 搜尋取出結果的數量
var queryLimit = 20;
// 開始搜尋!
var hits = indexSearcher.Search(parser, queryLimit);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
最後的結果(Hits),是需要再回到Document去撈出對應的資料喔!
是不是非常簡單呢?
筆者寫了一個簡單的範例在GitHub上,秉持著追求新技術的心使用了.Net 6,還請各位大大多多包涵。
有中英文兩種Repository,只需要在上方的DI注入切換就可以囉!
GitHub連結: https://github.com/g13579112000/Lucene
筆者第一次撰寫這種教學文章,有哪邊錯誤的非常歡迎一起來討論指教。
之後有機會再撰寫Lucene更深入的應用方面,
例如權重的分配與分詞器的選擇與使用。
感謝您的閱讀。
參考文獻:
1.黑暗大大的全文檢索筆記: https://blog.darkthread.net/blog/lucene-net-notes-1/
2.使用.Net實現全文檢索: https://blog.csdn.net/huwei2003/article/details/53408388
3.伊凡的部落格: http://irfen.me/5-lucene4-9-learning-record-lucene-analysis-tokenizer/
4.純淨天空代碼範例: https://vimsky.com/zh-tw/examples/detail/csharp-ex-Lucene.Net.Documents-Document---class.html
梨子, 2022/2/24 下午 08:23:46
UW -> DB 物件產生器會產生兩個function
GetAllDataFromBaseTableWithCache(string OrderFields = "_Default", bool IsCopy = true )
以及
Get物件名稱FromCachedDT(string Key)
-----------------------------------------------------------
設計上是希望將所有資料Cache在記憶體,然後前端直接抓出資料,不須到資料庫抓資料
理論上網頁速度應該比較佳,實際上卻發現是效能殺手
原因在於 GetAllDataFromBaseTableWithCache 是抓出整個table的資料放到 Cache
然後又做了一件事,當有人要資料時,會把整個 DataTable 做 Copy() 再 return
也就是說,當DataTable有數千筆資料列時
每叫用一次 "Get物件名稱FromCachedDT(string Key)" 就會把數千筆資料整個複製一次
再從複製出來的DataTable Select 出一列 return
------------------------------------------------------------
解決方法:
Get物件名稱FromCachedDT(string Key) --> 改成一筆一筆資料做 Cache,這樣 Copy() 只會Copy一筆
實測上,原本頁面要跑1.8秒,調整後可以 0.4 秒就完成
-----------------------------------------------------------
結論:
PG產生器就把 GetAllDataFromBaseTableWithCache 拿掉吧
GetAllDataFromBaseTableWithCache(string OrderFields = "_Default", bool IsCopy = true )
以及
Get物件名稱FromCachedDT(string Key)
-----------------------------------------------------------
設計上是希望將所有資料Cache在記憶體,然後前端直接抓出資料,不須到資料庫抓資料
理論上網頁速度應該比較佳,實際上卻發現是效能殺手
原因在於 GetAllDataFromBaseTableWithCache 是抓出整個table的資料放到 Cache
然後又做了一件事,當有人要資料時,會把整個 DataTable 做 Copy() 再 return
也就是說,當DataTable有數千筆資料列時
每叫用一次 "Get物件名稱FromCachedDT(string Key)" 就會把數千筆資料整個複製一次
再從複製出來的DataTable Select 出一列 return
------------------------------------------------------------
解決方法:
Get物件名稱FromCachedDT(string Key) --> 改成一筆一筆資料做 Cache,這樣 Copy() 只會Copy一筆
實測上,原本頁面要跑1.8秒,調整後可以 0.4 秒就完成
-----------------------------------------------------------
結論:
PG產生器就把 GetAllDataFromBaseTableWithCache 拿掉吧
darren, 2018/5/21 下午 03:17:00
又發現新說法
我們在 front-end 做 scroll event的監聽的時候很常會過度的觸發要執行的事情,因此導致效能不太佳,
我們需要的是固定頻率執行某個function , 這個原來叫 throttle
另外一種狀況像是autocomplete,不需要每一個keyup 都去ajax 去backend 抓資料回來,所以我們過去,
設一個變數去記住setTimeout 回傳回來的數字,如果下一次的keyup 發生在預設的時間內就去把 setTimeout清掉。
原來這種做法,有一個稱呼叫 debounce
不過jQuery 沒有內建這兩個function。這樣在複雜的 js 中增加易讀性。
我們在 front-end 做 scroll event的監聽的時候很常會過度的觸發要執行的事情,因此導致效能不太佳,
我們需要的是固定頻率執行某個function , 這個原來叫 throttle
另外一種狀況像是autocomplete,不需要每一個keyup 都去ajax 去backend 抓資料回來,所以我們過去,
設一個變數去記住setTimeout 回傳回來的數字,如果下一次的keyup 發生在預設的時間內就去把 setTimeout清掉。
原來這種做法,有一個稱呼叫 debounce
不過jQuery 沒有內建這兩個function。這樣在複雜的 js 中增加易讀性。
瞇瞇, 2015/4/6 下午 08:19:47
半夜被老闆 Line,跟我說網頁發生錯誤,他無法看統計報表,會出現作業逾時的錯誤 我查了一下網頁程式,發現是這筆SQL指令跑太久
Select Id, (IsNull(Total, 0) - IsNull(CouponDiscount, 0) + IsNull(CouponAdd, 0)) as Total, Buyer_Email, EN_Packing_List_Status, EN_Order_Source, En_Stock_Status, Create_Date
From V_Order_main With(Nolock)
Where Id in (select Order_Id from Ad_Trace With(NoLock) where (Parameter_Id = 14278))
AND Create_Date >= '2014/10/3' And Create_Date < '2014/10/12'
--> 跑了50秒~ 1分鐘
Select Id, (IsNull(Total, 0) - IsNull(CouponDiscount, 0) + IsNull(CouponAdd, 0)) as Total, Buyer_Email, EN_Packing_List_Status, EN_Order_Source, En_Stock_Status, Create_Date
From V_Order_main With(Nolock)
Where Id in (select Order_Id from Ad_Trace With(NoLock) where (Parameter_Id = 14278))
--> 拿掉日期限制 > 秒殺, 結果跑出 47 筆資料
跑一下執行計畫 原來子查詢的 Ad_Trace 沒有建立Index造成

加上 Index 之後,再跑第一支SQL --> 秒殺
奇怪的地方:
明明訂單日期欄位(Create_Date) 跟 Ad_Trace 沒有多大關係,但是加上日期限制之後,居然會引發 Ad_Trace 搜尋過久的現象
他好像是先依照訂單日期找出所有訂單,然後再從子查詢 Ad_Trace 裡面搜尋有無符合的條件訂單
而不是先跑子查詢找出 Ad_Trace 所有的 Order_Id,再去找符合 Create_Date 的訂單
SQL內部運作的機制真是有點讓人想不透,幸好有評估計畫可以看出問題在哪裡
這讓我想起以前學SQL時的一句話 => 盡量用Join來取代子查詢
使用子查詢真的是效能殺手啊
------繼續補充--------------------------------------
上面的SQL在雙11活動後,由於當日訂單過多,一樣造成SQL timeout 的現象,研判還是子查詢造成的問題
Select Id, (IsNull(Total, 0) - IsNull(CouponDiscount, 0) + IsNull(CouponAdd, 0)) as Total, Buyer_Email, EN_Packing_List_Status, EN_Order_Source, En_Stock_Status, Create_Date
From V_Order_main With(Nolock)
Where Id in (select Order_Id from Ad_Trace With(NoLock) where (Parameter_Id = 14720))
And Create_Date > '2014-11-10' And Create_Date < '2014-11-11'
--> 跑了51秒
所以先將子查詢拿出來跑出一串字串 865828,865890,865901,865903,865928,865955,865990,865993,866005,866035.....
(共1452筆)
再把他拼入sql跑 --> 7秒
darren, 2014/10/11 上午 09:58:18