搜尋 tim 結果:
static System.Security.Cryptography.RandomNumberGenerator RandomNumberGenerator = null;
/// <summary>
/// 回傳大於等於 0 小於 1
/// </summary>
/// <returns></returns>
public static double NextDouble()
{
if (RandomNumberGenerator == null || LastRandomGenerateTime < DateTime.Now.AddMinutes(-1))
{
RandomNumberGenerator = System.Security.Cryptography.RandomNumberGenerator.Create();
}
// Generate four random bytes
byte[] four_bytes = new byte[4];
RandomNumberGenerator.GetBytes(four_bytes);
// Convert the bytes to a UInt32
uint scale = BitConverter.ToUInt32(four_bytes, 0);
// And use that to pick a random number >= min and < max
// 0 <= (scale / (uint.MaxValue + 1.0)) < 1
return scale / (uint.MaxValue + 1.0);
}
/// <summary>
/// 回傳值介於 min ~ (max - 1)
/// </summary>
/// <param name="min"></param>
/// <param name="max"></param>
/// <returns></returns>
public static int GetRandomInt(int min, int max)
{
if(max < min)
{
throw new Exception("最大值不可小於最小值");
}
// Generate four random bytes
byte[] four_bytes = new byte[4];
RandomNumberGenerator.GetBytes(four_bytes);
// And use that to pick a random number >= min and < max
return (int)(min + (max - min) * NextDouble()); //因為 NextDouble 會小於 1,所以用無條件捨去.
}
/// <summary>
/// 產生 0 ~ (max - 1) 的亂數
/// </summary>
/// <param name="max"></param>
/// <returns></returns>
public static int GetRandomInt(int max)
{
return GetRandomInt(0, max);
}
/// <summary>
/// 產生 0 ~ (int.MaxValue - 1) 的亂數
/// </summary>
/// <returns></returns>
public static int GetRandomInt()
{
return GetRandomInt(int.MaxValue);
}
Bike, 2022/9/22 下午 08:30:03
.net 6 在 model 中上傳日期字串時,如果遇到 "The JSON value could not be converted to System.Nullable`1[System.DateTime]" 這個錯誤,解決方法如下:
1. 安裝套件: Microsoft.AspNetCore.Mvc.NewtonsoftJson
2. 在 program.cs 中,原來來的
builder.Services.AddControllers()
改為 (其 options 的部份非必要)
builder.Services.AddControllers()
.AddNewtonsoftJson(options =>
{
options.SerializerSettings.ContractResolver = new Su.CamelCaseContractResolver();
});
1. 安裝套件: Microsoft.AspNetCore.Mvc.NewtonsoftJson
2. 在 program.cs 中,原來來的
builder.Services.AddControllers()
改為 (其 options 的部份非必要)
builder.Services.AddControllers()
.AddNewtonsoftJson(options =>
{
options.SerializerSettings.ContractResolver = new Su.CamelCaseContractResolver();
});
Bike, 2022/8/21 下午 10:12:43
-- 自動更新某個欄位
CREATE OR REPLACE FUNCTION before_market_update ()
RETURNS TRIGGER AS
$$
BEGIN
NEW.LMDT = LocalTimeStamp;
RETURN NEW;
END;
$$
LANGUAGE 'plpgsql';
CREATE TRIGGER updt_market
BEFORE UPDATE
ON "Market"
FOR EACH ROW
EXECUTE PROCEDURE before_market_update();
CREATE OR REPLACE FUNCTION before_market_update ()
RETURNS TRIGGER AS
$$
BEGIN
NEW.LMDT = LocalTimeStamp;
RETURN NEW;
END;
$$
LANGUAGE 'plpgsql';
CREATE TRIGGER updt_market
BEFORE UPDATE
ON "Market"
FOR EACH ROW
EXECUTE PROCEDURE before_market_update();
Bike, 2022/8/12 下午 09:25:57
--建立 table (要記得改 XXX)
CREATE TABLE IF NOT EXISTS public.table_monitor
(
table_name text COLLATE pg_catalog."default" NOT NULL,
update_at timestamp without time zone NOT NULL DEFAULT now(),
update_count bigint NOT NULL DEFAULT 0,
CONSTRAINT table_monitor_pkey PRIMARY KEY (table_name)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.table_monitor
OWNER to XXX;
-- 這一段只要執行一次
CREATE OR REPLACE FUNCTION public.table_monitor_trigger_fnc()
RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
-- 1️⃣ 避免監控 table_monitor 自己造成遞迴
IF TG_TABLE_NAME = 'table_monitor' THEN
RETURN NEW;
END IF;
-- 2️⃣ 直接 update(安全遞增)
UPDATE public.table_monitor
SET update_count = update_count + 1,
update_at = now()
WHERE table_name = TG_TABLE_NAME;
RETURN NEW;
END;
$$;
ALTER FUNCTION public.table_monitor_trigger_fnc()
OWNER TO XXX;
-- 對於被監控的 table, 要執行以下的指令,記得 monitor_table_name 要改為 table 的名字(要符合大小寫)
INSERT INTO public.table_monitor (table_name, update_at, update_count) VALUES ('monitor_table_name', '2000-01-01', 0) ON CONFLICT DO NOTHING;
CREATE OR REPLACE TRIGGER table_monitor_trigger
AFTER INSERT OR DELETE OR UPDATE
ON monitor_table_name
FOR EACH STATEMENT
EXECUTE FUNCTION public.table_monitor_trigger_fnc();
監控用的程式碼:
CREATE TABLE IF NOT EXISTS public.table_monitor
(
table_name text COLLATE pg_catalog."default" NOT NULL,
update_at timestamp without time zone NOT NULL DEFAULT now(),
update_count bigint NOT NULL DEFAULT 0,
CONSTRAINT table_monitor_pkey PRIMARY KEY (table_name)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.table_monitor
OWNER to XXX;
-- 這一段只要執行一次
CREATE OR REPLACE FUNCTION public.table_monitor_trigger_fnc()
RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
-- 1️⃣ 避免監控 table_monitor 自己造成遞迴
IF TG_TABLE_NAME = 'table_monitor' THEN
RETURN NEW;
END IF;
-- 2️⃣ 直接 update(安全遞增)
UPDATE public.table_monitor
SET update_count = update_count + 1,
update_at = now()
WHERE table_name = TG_TABLE_NAME;
RETURN NEW;
END;
$$;
ALTER FUNCTION public.table_monitor_trigger_fnc()
OWNER TO XXX;
-- 對於被監控的 table, 要執行以下的指令,記得 monitor_table_name 要改為 table 的名字(要符合大小寫)
INSERT INTO public.table_monitor (table_name, update_at, update_count) VALUES ('monitor_table_name', '2000-01-01', 0) ON CONFLICT DO NOTHING;
CREATE OR REPLACE TRIGGER table_monitor_trigger
AFTER INSERT OR DELETE OR UPDATE
ON monitor_table_name
FOR EACH STATEMENT
EXECUTE FUNCTION public.table_monitor_trigger_fnc();
監控用的程式碼:
public static void UpdateTableCache()
{
//標記自已是正在執行的 Thread. 讓舊的 Thread 在執行完畢之後, 應該會自動結束. 以防舊的 Thread 執行超過 10 秒.
CurrentThreadId = System.Threading.Thread.CurrentThread.ManagedThreadId;
try
{
//確認自已是正在執行的 Thread, 重覆執行. (另一個 Thread 插入執行)
while (CurrentThreadId == System.Threading.Thread.CurrentThread.ManagedThreadId)
{
LastUpdateDate = DateTime.Now;
foreach (var dbId in CachedDbs)
{
var sql = @"select * from table_monitor";
var dt = Su.PgSql.DtFromSql(sql, dbId);
foreach (DataRow row in dt.Rows)
{
string changeId = row["update_count"].DBNullToDefault();
string CacheKey = TableCacheKey(dbId, row["table_name"].DBNullToDefault());
ObjectCache cache = MemoryCache.Default;
string OldValue = (string)cache[CacheKey];
if (OldValue == null)
{
cache.Set(CacheKey, changeId, DateTime.MaxValue);
}
else
{
if (changeId != OldValue)
{
cache.Remove(CacheKey);
cache.Set(CacheKey, changeId, DateTime.MaxValue);
}
}
}
}
//每兩秒檢查一次
System.Threading.Thread.Sleep(2000);
}
}
catch (Exception)
{
//依經驗, 只要 DB 能通, 這裡幾乎不會有問題, 所以這裡暫時不處理, 未來有問題時可以考慮寫入文字檔比較好.
}
}
Bike, 2022/7/20 上午 10:05:39
上一集當中我們完成了Lucene基本操作中的Create與Read,這一集會將CRUD中的Update與Delete的操作方法告訴你,並且本集會著重於講解關於"Norms"與權重(Boost)在Lucene中的運作概念。
首先我們建立一個.Net 6的主控台應用程式
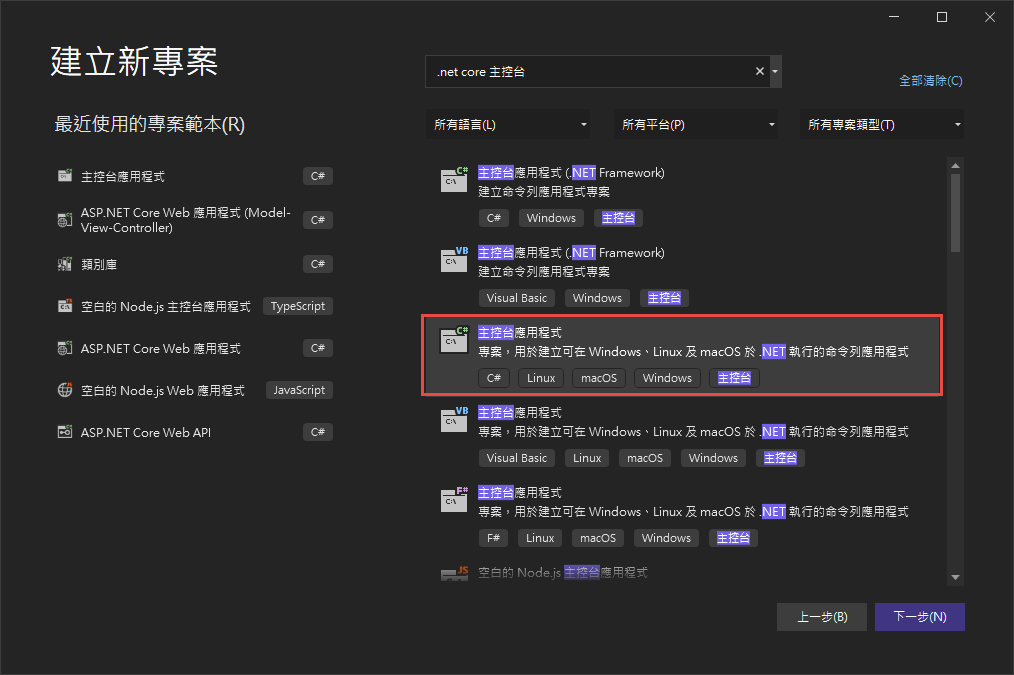
建立好後於右側專案右鍵選擇"管理Nuget套件",並選擇"瀏覽">於搜索列中搜尋"Lucene">安裝3.0.3最新穩定版 與 "System.Configuration.ConfigurationManager"
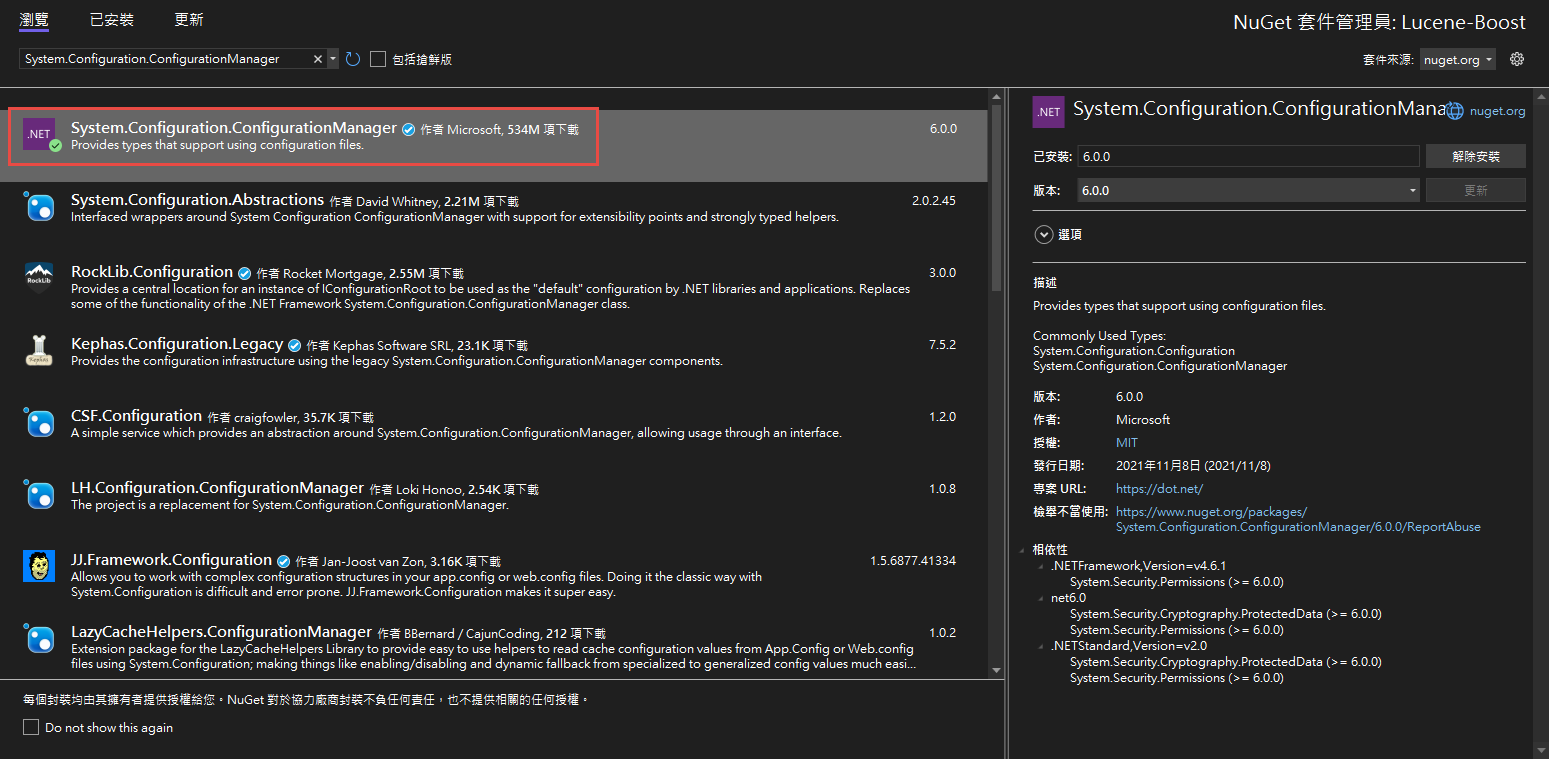
安裝好後就可以於專案內使用Lucene套件囉!
再來依照上一篇的教學建立一套簡單的Lucene查詢
好囉! 接下來我們要如何更新索引呢?
更新其實就是將存在的索引刪除並重新建立Document,不存在的則直接新增。
首先準備一組資料準備更新
*欲更新的Document必須與創建所引時使用的Document欄位相同*
來測試看看
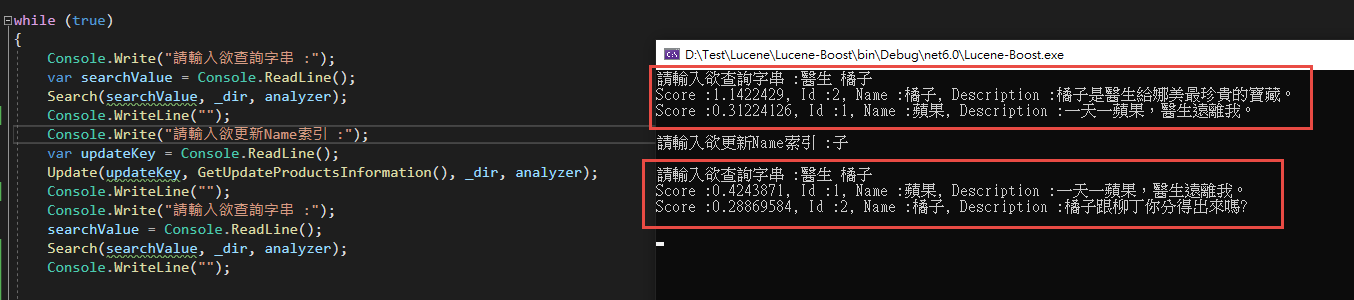
可以看見 Name = 橘子 的索引已經改為我們新準備的資料囉。
再來是刪除!
與更新非常相似,只需要使用deleteDocument()就可以了。
再來看看輸出結果
可以發現 Score :0.7554128, Id :2, Name :橘子, Description :醫生給娜美最珍貴的寶藏。這筆索引已經被移除囉!
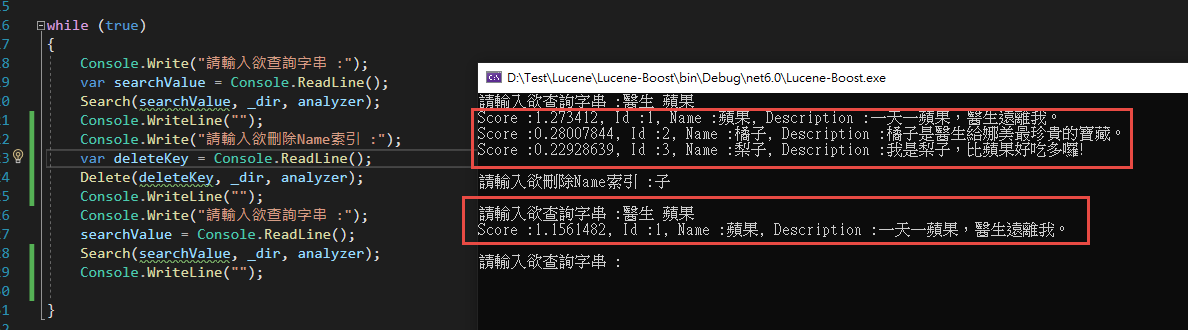
可以發現筆者於更新或刪除時都是輸入單一字來做異動,除了表達可以對索引做複合更動外,
是因為更新與刪除索引同樣會使用到分詞器(analyzer),
*所輸入的索引值非ID等數值時必須要配合分詞器的分詞能力*才能取得所想異動的索引喔!
Boost是什麼呢?
Boost 分為 :
1. Index Time Boost : 在建立索引時就計算好的值。例如上一篇中提到的(NORMS)
2. Query Time Boost : 查詢時賦與搜尋條件不同的值以影響結果。
我們先來測試Index Time Boost的部分
並記得重新CreateIndex才能刷新欄位的權重值喔。
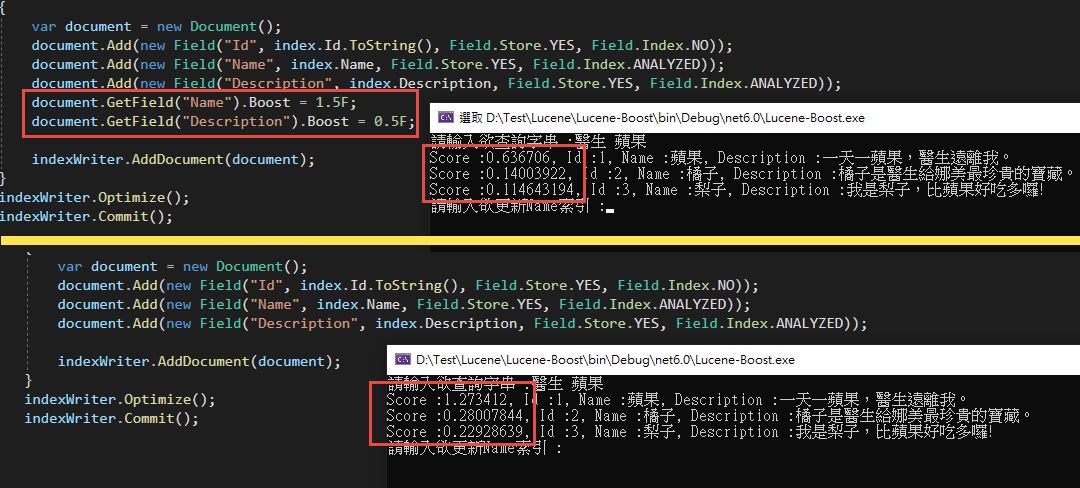
很明顯的搜尋出來的Score分數變動了! 但是有沒有發現明明Name欄位的Boost改成了1.5,蘋果的數值卻仍然只有一半呢?
這是因為我們的Search中所參照的欄位為Description,所以在計算Score的時候其實是完全沒有參與的喔!
另外要記得,使用Index Time Boost的時候,欲給予銓重分配的欄位Field.Index不能使用NO_NORMS,不然這個欄位並不會紀錄權重的資料。
再來我們試試看Query Time Boost
這次我們搜尋兩個欄位"Name"與"Description",並使用 BooleanQuery來將其組合。
BooleanQuery中的 Occur有三種參數 : "MUST","MUST_NOT","SHOULD",功能與字面上的意思一樣為"必須要有","必須沒有"與"有無都包含"。

查詢出來的分數就不一樣囉!
以上就是這一次的分享,Lucene是一款容易入門但是要實際上戰場卻又十分複雜的功能,想要達成真正高效能的全文檢索,在前期的文件規畫配置與資料的權重配比都是一個巨大的挑戰。未來會繼續分享關於Lucene的其他有趣功能,還請繼續期待呦!
另外也可以到GitHub下載我的範例來參考呦!
GitHub: https://github.com/g13579112000/Lucene
參考文件:
1. 黑暗大大的全文檢索筆記 : https://blog.darkthread.net/blog/lucene-net-notes-1/
2. Makble : http://makble.com/lucene-field-boost-example
3. CSDN Jack2013tong 文章 : https://blog.csdn.net/huwei2003/article/details/53408388
首先我們建立一個.Net 6的主控台應用程式
建立好後於右側專案右鍵選擇"管理Nuget套件",並選擇"瀏覽">於搜索列中搜尋"Lucene">安裝3.0.3最新穩定版 與 "System.Configuration.ConfigurationManager"
安裝好後就可以於專案內使用Lucene套件囉!
再來依照上一篇的教學建立一套簡單的Lucene查詢
using Lucene.Net.Analysis.Standard;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.QueryParsers;
using Lucene.Net.Search;
using Lucene.Net.Store;
var _dir = new DirectoryInfo("LuceneDocument");
if (!File.Exists(_dir.FullName))
{
System.IO.Directory.CreateDirectory(_dir.FullName);
}
var analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_CURRENT);
CreateIndex(GetProductsInformation(), _dir, analyzer);
while (true)
{
Console.Write("請輸入欲查詢字串 :");
var searchValue = Console.ReadLine();
Search(searchValue, _dir, analyzer);
}
void CreateIndex(List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
void Search(string searchValue, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(_dir))
{
var parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
using (var indexSearcher = new IndexSearcher(directory))
{
var queryLimit = 20;
var hits = indexSearcher.Search(parser, queryLimit);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
}
}
}
List<Product> GetProductsInformation()
{
return new List<Product> {
new Product{ Id = 1, Name = "蘋果", Description = "一天一蘋果,醫生遠離我。"},
new Product{ Id = 2, Name = "橘子", Description = "醫生給娜美最珍貴的寶藏。"},
new Product{ Id = 3, Name = "梨子", Description = "我是梨子,比蘋果好吃多囉!"},
new Product{ Id = 4, Name = "葡萄", Description = "吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮"},
new Product{ Id = 5, Name = "榴槤", Description = "水果界的珍寶!好吃一直吃。"}
};
}
class Product
{
public long Id { get; set; }
public string Name { get; set; } = null!;
public string Description { get; set; } = null!;
}
好囉! 接下來我們要如何更新索引呢?
更新其實就是將存在的索引刪除並重新建立Document,不存在的則直接新增。
首先準備一組資料準備更新
List<Product> GetUpdateProductsInformation()
{
return new List<Product>
{
new Product{ Id = 6, Name = "香蕉", Description = "運動完後吃根香蕉補充養分。"},
new Product{ Id = 2, Name = "橘子", Description = "橘子跟柳丁你分得出來嗎?"}
};
}
*欲更新的Document必須與創建所引時使用的Document欄位相同*
void Update(string key, List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using( var directory = FSDirectory.Open(dir))
{
using(var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
indexWriter.UpdateDocument(new Term("Name", key) ,document);
}
}
}
}
來測試看看
可以看見 Name = 橘子 的索引已經改為我們新準備的資料囉。
再來是刪除!
與更新非常相似,只需要使用deleteDocument()就可以了。
void Delete(string key, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
indexWriter.DeleteDocuments(new Term("Name", key));
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
再來看看輸出結果
可以發現 Score :0.7554128, Id :2, Name :橘子, Description :醫生給娜美最珍貴的寶藏。這筆索引已經被移除囉!
可以發現筆者於更新或刪除時都是輸入單一字來做異動,除了表達可以對索引做複合更動外,
是因為更新與刪除索引同樣會使用到分詞器(analyzer),
*所輸入的索引值非ID等數值時必須要配合分詞器的分詞能力*才能取得所想異動的索引喔!
Boost是什麼呢?
Boost 分為 :
1. Index Time Boost : 在建立索引時就計算好的值。例如上一篇中提到的(NORMS)
2. Query Time Boost : 查詢時賦與搜尋條件不同的值以影響結果。
我們先來測試Index Time Boost的部分
void CreateIndexWithBoost(List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
document.GetField("Name").Boost = 1.5F;
document.GetField("Description").Boost = 0.5F;
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
並記得重新CreateIndex才能刷新欄位的權重值喔。
很明顯的搜尋出來的Score分數變動了! 但是有沒有發現明明Name欄位的Boost改成了1.5,蘋果的數值卻仍然只有一半呢?
這是因為我們的Search中所參照的欄位為Description,所以在計算Score的時候其實是完全沒有參與的喔!
另外要記得,使用Index Time Boost的時候,欲給予銓重分配的欄位Field.Index不能使用NO_NORMS,不然這個欄位並不會紀錄權重的資料。
再來我們試試看Query Time Boost
void SearchWithBoost(string searchValue, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(_dir))
{
using (var indexSearcher = new IndexSearcher(directory))
{
var query = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Name", analyzer).Parse(searchValue);
var query2 = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
query.Boost = 2.0F;
query2.Boost = 0.5F;
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.Add(query, Occur.SHOULD);
booleanQuery.Add(query2, Occur.SHOULD);
var hits = indexSearcher.Search(booleanQuery, 20);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
}
}
}
這次我們搜尋兩個欄位"Name"與"Description",並使用 BooleanQuery來將其組合。
BooleanQuery中的 Occur有三種參數 : "MUST","MUST_NOT","SHOULD",功能與字面上的意思一樣為"必須要有","必須沒有"與"有無都包含"。
查詢出來的分數就不一樣囉!
以上就是這一次的分享,Lucene是一款容易入門但是要實際上戰場卻又十分複雜的功能,想要達成真正高效能的全文檢索,在前期的文件規畫配置與資料的權重配比都是一個巨大的挑戰。未來會繼續分享關於Lucene的其他有趣功能,還請繼續期待呦!
另外也可以到GitHub下載我的範例來參考呦!
GitHub: https://github.com/g13579112000/Lucene
參考文件:
1. 黑暗大大的全文檢索筆記 : https://blog.darkthread.net/blog/lucene-net-notes-1/
2. Makble : http://makble.com/lucene-field-boost-example
3. CSDN Jack2013tong 文章 : https://blog.csdn.net/huwei2003/article/details/53408388
梨子, 2022/4/20 下午 09:34:03
Lucene.Net是一套C#開源全文索引庫,其主要包含了:
· Index : 提供索引的管理與詞組的排序
· Search : 提供查詢相關功能
· Store : 支援資料儲存管理,包括I/O操作
· Util : 共用套件
· Documents : 負責描述索引儲存時的文件結構管理
· QueryParsers : 提供查詢語法
· Analysis : 負責分析內容
要達到高效能的全文檢索讓機器可以明白我們的語言,最重要的關鍵就是"分詞器"了。
試想一下這一句話你會如何拆分成一段一段的關鍵字呢?
"一天一蘋果,醫生遠離我"
還有英文版本
"An apple a day, doctor keep me away."
中文版本的拆分:
"一天"、"一"、"蘋果"、"醫生"、"遠離"、"我"
英文版本的拆分:
"apple"、"day"、"doctor"、"keep"、"me"、"away"
有沒有注意到不同語系所分析出來的關鍵字有一點不一樣呢?
而在Lucene中分詞的工作會交給Analysis來完成,
不過我們可以依照不同的語系去選擇想使用的分詞器(Analyzer)!
首先簡單說明一下Lucene的實作流程
1. 確認主要搜尋的語系來決定使用的分詞器(analyzer)
2. 建立Document依照analyzer匯入資料
(前置完成)
3. 建立IndexSearcher導入準備好的Document
4. 建立Parser來分析SearchValue
5. 使用IndexSearcher分析Parser取得結果(Hits)
*本專案使用的是Lucene.Net 3.0.3*
接下來我們來建立一個提供查詢使用的Document。
如此一來我們就建立好Lucene的基本配備囉!
其中analyzer的部分我們使用Lucene.Net預設,
要特別注意的是,其處理中文語系的能力非常之爛!
之後再寫一篇文章深入探討。
再來值得一提的是
前兩個參數就是Key跟Value,可以簡單理解為欄位與其內容。
後面兩個參數是重點!
Store: 代表是否儲存這個Key的Value
例如在google打上台南美食會搜索出許多不同的文章連結,
不過google給你的資料中最重要的不是文章內容(Description),
而是哪一篇文章(Name)與台南美食最有關係。
假如今天我只要回傳一個列表而不用提示文章中有哪些內容,
那麼我就可以選擇給"Description" Field.Store.No來節省空間。
Index:
· NO - 不加入索引,這個內容只需要隨著結果出爐,不需要在查詢的時候被考慮。
· ANALYZED、NOT_ANALYZED - 是否使用分詞
· NO_NORMS - 關閉權重功能
或許許多人會對權重功能(NORMS)感到疑惑,
簡單的舉個例子
{ Id=1, Key="蘋果", Value="一天一蘋果,醫生遠離我。"}
{ Id=2, Key="橘子", Value="醫生給娜美最珍貴的寶藏。"}
{ Id=3, Key="梨子", Value="我是梨子,比蘋果蘋果好吃多囉!"}
當我搜尋"蘋果"的時候結果會是
{ Id=1, MatchKey=1, MatchValue=1, Score=(1*5) + (1*2) = 7}
{ Id=3, MatchKey=0, MatchValue=1, Score=(0*5) + (2*2) = 4}
有發現了嗎?
雖然同樣都對中兩個結果但是Id 1的資料Key值中有包含關鍵字,
因此得到較高的分數排在Id 3前方
準備好Document了,我們可以開始來實際使用看看囉!
最後的結果(Hits),是需要再回到Document去撈出對應的資料喔!
是不是非常簡單呢?
筆者寫了一個簡單的範例在GitHub上,秉持著追求新技術的心使用了.Net 6,還請各位大大多多包涵。
有中英文兩種Repository,只需要在上方的DI注入切換就可以囉!
GitHub連結: https://github.com/g13579112000/Lucene
筆者第一次撰寫這種教學文章,有哪邊錯誤的非常歡迎一起來討論指教。
之後有機會再撰寫Lucene更深入的應用方面,
例如權重的分配與分詞器的選擇與使用。
感謝您的閱讀。
參考文獻:
1.黑暗大大的全文檢索筆記: https://blog.darkthread.net/blog/lucene-net-notes-1/
2.使用.Net實現全文檢索: https://blog.csdn.net/huwei2003/article/details/53408388
3.伊凡的部落格: http://irfen.me/5-lucene4-9-learning-record-lucene-analysis-tokenizer/
4.純淨天空代碼範例: https://vimsky.com/zh-tw/examples/detail/csharp-ex-Lucene.Net.Documents-Document---class.html
· Index : 提供索引的管理與詞組的排序
· Search : 提供查詢相關功能
· Store : 支援資料儲存管理,包括I/O操作
· Util : 共用套件
· Documents : 負責描述索引儲存時的文件結構管理
· QueryParsers : 提供查詢語法
· Analysis : 負責分析內容
要達到高效能的全文檢索讓機器可以明白我們的語言,最重要的關鍵就是"分詞器"了。
試想一下這一句話你會如何拆分成一段一段的關鍵字呢?
"一天一蘋果,醫生遠離我"
還有英文版本
"An apple a day, doctor keep me away."
中文版本的拆分:
"一天"、"一"、"蘋果"、"醫生"、"遠離"、"我"
英文版本的拆分:
"apple"、"day"、"doctor"、"keep"、"me"、"away"
有沒有注意到不同語系所分析出來的關鍵字有一點不一樣呢?
而在Lucene中分詞的工作會交給Analysis來完成,
不過我們可以依照不同的語系去選擇想使用的分詞器(Analyzer)!
首先簡單說明一下Lucene的實作流程
1. 確認主要搜尋的語系來決定使用的分詞器(analyzer)
2. 建立Document依照analyzer匯入資料
(前置完成)
3. 建立IndexSearcher導入準備好的Document
4. 建立Parser來分析SearchValue
5. 使用IndexSearcher分析Parser取得結果(Hits)
*本專案使用的是Lucene.Net 3.0.3*
接下來我們來建立一個提供查詢使用的Document。
// 取得或建立Lucene文件資料夾
if (!File.Exists(_dir.FullName))
{
System.IO.Directory.CreateDirectory(_dir.FullName);
}
// Asp.Net Core需要於Nuget安裝System.Configuration.ConfigurationManager提供用戶端應用程式的組態檔存取
Lucene.Net.Store.Directory directory = FSDirectory.Open(_dir);
// 選擇分詞器
var analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_CURRENT);
// 資料來源
var repository = new Repository();
// 依照指定的文件結構來建立
var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);
foreach (var index in repository)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.NO, Field.Index.ANALYZED));
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
indexWriter.Dispose();
如此一來我們就建立好Lucene的基本配備囉!
其中analyzer的部分我們使用Lucene.Net預設,
要特別注意的是,其處理中文語系的能力非常之爛!
之後再寫一篇文章深入探討。
再來值得一提的是
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));前兩個參數就是Key跟Value,可以簡單理解為欄位與其內容。
後面兩個參數是重點!
Store: 代表是否儲存這個Key的Value
例如在google打上台南美食會搜索出許多不同的文章連結,
不過google給你的資料中最重要的不是文章內容(Description),
而是哪一篇文章(Name)與台南美食最有關係。
假如今天我只要回傳一個列表而不用提示文章中有哪些內容,
那麼我就可以選擇給"Description" Field.Store.No來節省空間。
Index:
· NO - 不加入索引,這個內容只需要隨著結果出爐,不需要在查詢的時候被考慮。
· ANALYZED、NOT_ANALYZED - 是否使用分詞
· NO_NORMS - 關閉權重功能
或許許多人會對權重功能(NORMS)感到疑惑,
簡單的舉個例子
{ Id=1, Key="蘋果", Value="一天一蘋果,醫生遠離我。"}
{ Id=2, Key="橘子", Value="醫生給娜美最珍貴的寶藏。"}
{ Id=3, Key="梨子", Value="我是梨子,比蘋果蘋果好吃多囉!"}
當我搜尋"蘋果"的時候結果會是
{ Id=1, MatchKey=1, MatchValue=1, Score=(1*5) + (1*2) = 7}
{ Id=3, MatchKey=0, MatchValue=1, Score=(0*5) + (2*2) = 4}
有發現了嗎?
雖然同樣都對中兩個結果但是Id 1的資料Key值中有包含關鍵字,
因此得到較高的分數排在Id 3前方
準備好Document了,我們可以開始來實際使用看看囉!
// 決定所要搜索的欄位
var parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
// 提供剛剛建立的Document
var indexSearcher = new IndexSearcher(directory);
// 搜尋取出結果的數量
var queryLimit = 20;
// 開始搜尋!
var hits = indexSearcher.Search(parser, queryLimit);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
最後的結果(Hits),是需要再回到Document去撈出對應的資料喔!
是不是非常簡單呢?
筆者寫了一個簡單的範例在GitHub上,秉持著追求新技術的心使用了.Net 6,還請各位大大多多包涵。
有中英文兩種Repository,只需要在上方的DI注入切換就可以囉!
GitHub連結: https://github.com/g13579112000/Lucene
筆者第一次撰寫這種教學文章,有哪邊錯誤的非常歡迎一起來討論指教。
之後有機會再撰寫Lucene更深入的應用方面,
例如權重的分配與分詞器的選擇與使用。
感謝您的閱讀。
參考文獻:
1.黑暗大大的全文檢索筆記: https://blog.darkthread.net/blog/lucene-net-notes-1/
2.使用.Net實現全文檢索: https://blog.csdn.net/huwei2003/article/details/53408388
3.伊凡的部落格: http://irfen.me/5-lucene4-9-learning-record-lucene-analysis-tokenizer/
4.純淨天空代碼範例: https://vimsky.com/zh-tw/examples/detail/csharp-ex-Lucene.Net.Documents-Document---class.html
梨子, 2022/2/24 下午 08:23:46
1. 增加 dateTimeFormat, isAutoToDate
2. 增加 static string ExportDateTimeFormat
2. 增加 static string ExportDateTimeFormat
Bike, 2022/1/6 上午 11:21:07
1. .Net Core 5.0 使用.
2. 可切換後, 適用於 MsSQL, MySql, Oracle
3. 預設所有 SQL 執行時要經過 SQL Injection 檢查.
(移除 "CheckDangerSQL", 併入 IsSqlInjection)
預設會把 CR 和 LF 換成 空白,以免 sql injection 檢查發生錯誤, 有參數可以控制這個行為。sql 和 資料應該要分開,sql 中的 CR 和 LF 被換成空白應該不會有問題。
4. 不要再使用 SqlStr, 改用 SqlValue (避免誤用, SqlStr 有一個問題, 若是忘了加上 '' 會有可能造成 sql injection)
5. ORM 的 Class Name, 若遇到全大寫的字節, 要先轉小寫, 再把第一個字母變大寫.
6. CopyPropertiesTo, CopyTo..
SetValue 時, 若發生錯誤, 要顯示錯誤欄位名稱. (Tmi 的版本, ObjUtil.cs)
7. CopyFromDataRow:
string 自動轉 DateTime
string 自動轉 int, long, decimal..
8. Criteria 的 In 和 operator (|) 要接 list 做為參數, 不要再直接用字串做參數.
9. OrderBy 增加 by column 且可以多個串接
10. Update 時可以用 sql 語法 (參考聖宜的 GetSetFieldWithExpression)
11. 檢查 SQL Injection 的方法改為先把 \r 和 \n 用空白取代,再檢查, 再取代參數。
12. DtFromSql 和 ExecuteSql 傳入 connection 和 transaction 的版本先刪除,未來有需要再增加。
2. 可切換後, 適用於 MsSQL, MySql, Oracle
3. 預設所有 SQL 執行時要經過 SQL Injection 檢查.
(移除 "CheckDangerSQL", 併入 IsSqlInjection)
預設會把 CR 和 LF 換成 空白,以免 sql injection 檢查發生錯誤, 有參數可以控制這個行為。sql 和 資料應該要分開,sql 中的 CR 和 LF 被換成空白應該不會有問題。
4. 不要再使用 SqlStr, 改用 SqlValue (避免誤用, SqlStr 有一個問題, 若是忘了加上 '' 會有可能造成 sql injection)
5. ORM 的 Class Name, 若遇到全大寫的字節, 要先轉小寫, 再把第一個字母變大寫.
6. CopyPropertiesTo, CopyTo..
SetValue 時, 若發生錯誤, 要顯示錯誤欄位名稱. (Tmi 的版本, ObjUtil.cs)
7. CopyFromDataRow:
string 自動轉 DateTime
string 自動轉 int, long, decimal..
8. Criteria 的 In 和 operator (|) 要接 list 做為參數, 不要再直接用字串做參數.
9. OrderBy 增加 by column 且可以多個串接
10. Update 時可以用 sql 語法 (參考聖宜的 GetSetFieldWithExpression)
11. 檢查 SQL Injection 的方法改為先把 \r 和 \n 用空白取代,再檢查, 再取代參數。
12. DtFromSql 和 ExecuteSql 傳入 connection 和 transaction 的版本先刪除,未來有需要再增加。
Bike, 2021/10/18 下午 04:29:15
以下的程式碼, 直接 alert(this.errorMessages); 會造成 chrome 卡住..
使用 setTimeout 延後 alert 可以解決這個問題. 但必需延後足夠的時間. 已知 200 ms 依然會卡住.
使用 setTimeout 延後 alert 可以解決這個問題. 但必需延後足夠的時間. 已知 200 ms 依然會卡住.
errorMessages: "",
failProcess: function (ret) {
console.log("failProcess start: " + new Date().getSeconds() + "." + new Date().getMilliseconds());
var json = ret.responseJSON;
if (json && json.invalidatedPayloads) {
var errors = json.invalidatedPayloads.filter(function F(x) {
return x.messages.length > 0
});
console.log("bdfore add class: " + new Date().getSeconds() + "." + new Date().getMilliseconds());
errors.map(function (x) {
return $("[name='" + x.name + "']").addClass("error");
});
console.log("after add class: " + new Date().getSeconds() + "." + new Date().getMilliseconds());
errorMessages = errors.map(function (x) {
return x.messages.join('\r\n');
}).join('\r\n');
console.log("afger build errorMessages: " + new Date().getSeconds() + "." + new Date().getMilliseconds());
console.log(errorMessages);
//alert(this.errorMessages);
window.setTimeout(api.alertError, 500);
console.log("after alert: " + new Date().getSeconds() + "." + new Date().getMilliseconds());
}
console.log("failProcess end: " + new Date().getSeconds() + "." + new Date().getMilliseconds());
},
Bike, 2021/9/29 下午 08:45:07
對 DateTime 的 property 直接設定 Require 的 Validation 會失敗. 因為茌是 client 送來空白, 會發生轉型的錯誤, 而不是 Require 的錯誤
可以把該 property 改設定為 DateTime? 來解決這個問題.
可以把該 property 改設定為 DateTime? 來解決這個問題.
Bike, 2021/9/23 下午 10:26:41