搜尋 table 結果:
這裡是我測試 Gmail API 和 Google API 憑証的一些記錄。
如果你的目的是要使用 Gmail Api 取代舊的 Gmail SMTP 來發送通知信,建議你先跳到最下方看一下結論。
如果你是想要看一下 Gmail API 和 Google API 憑証的使用方法,可以看一下這篇文章。
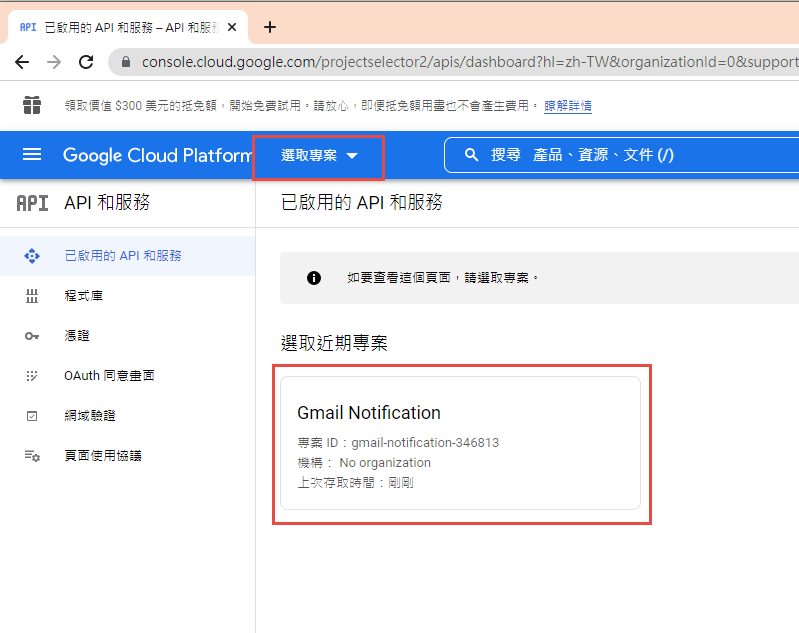
1. 在 google cloud platform 建立新的專案.
https://console.cloud.google.com/
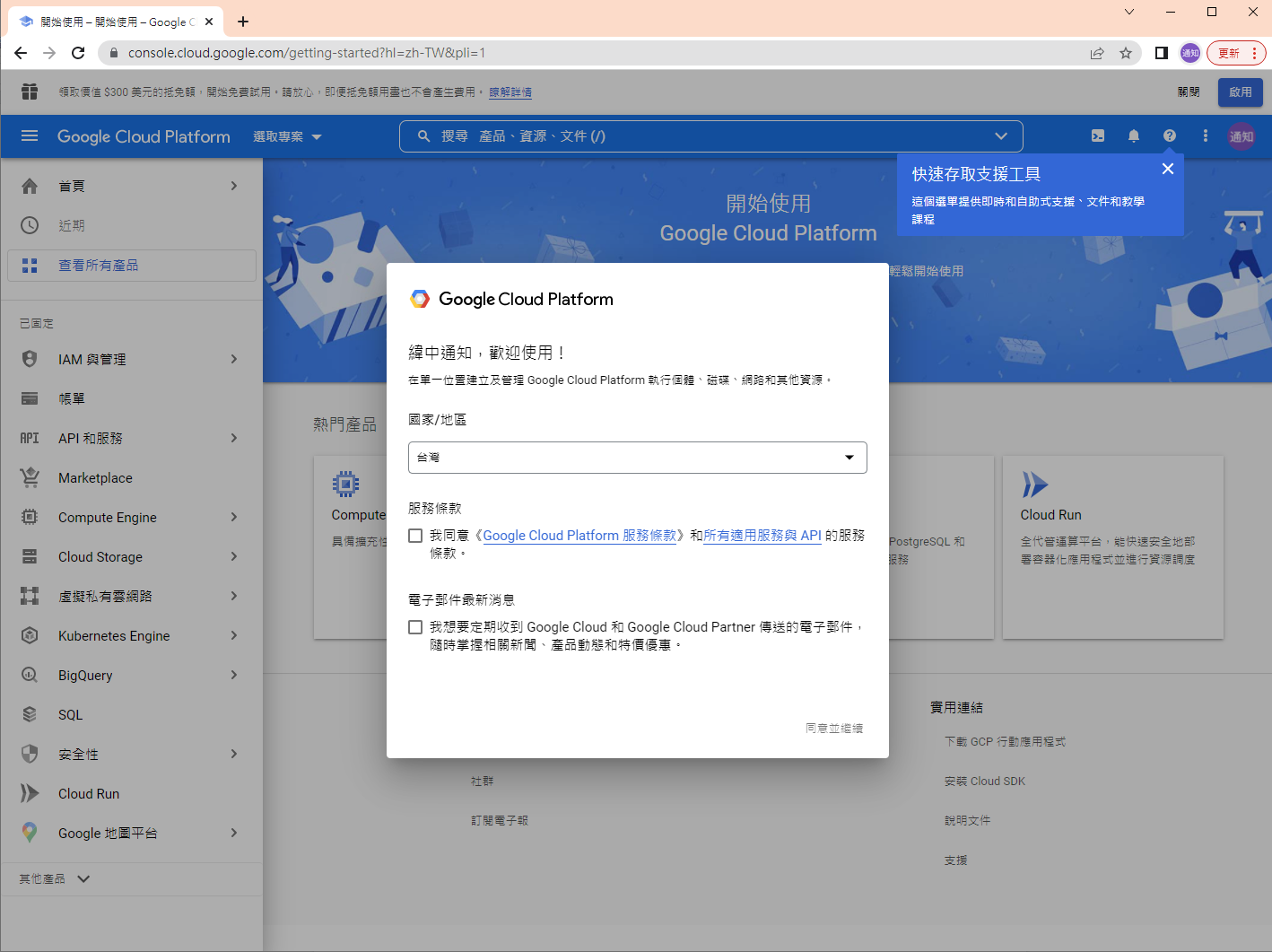
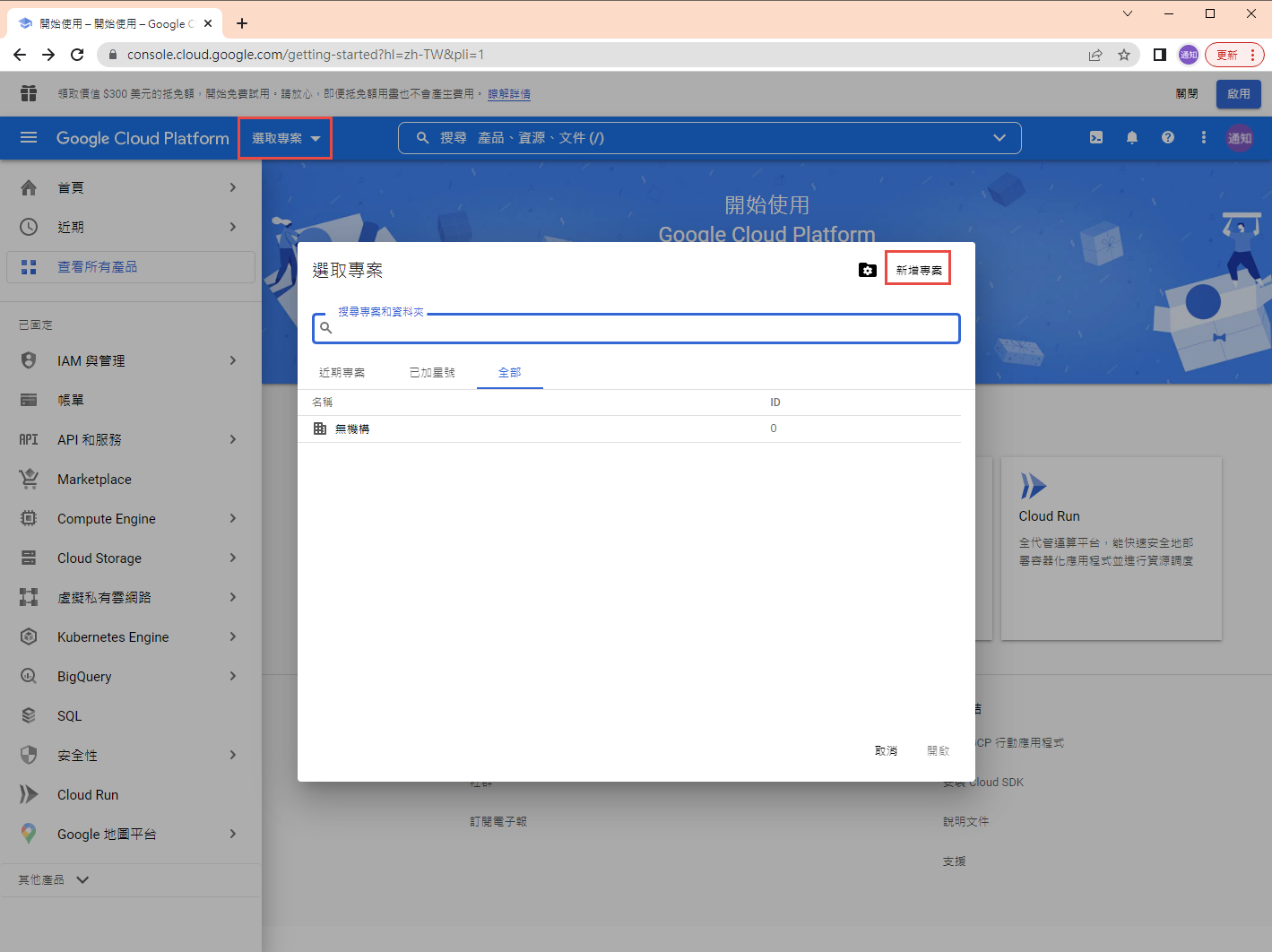
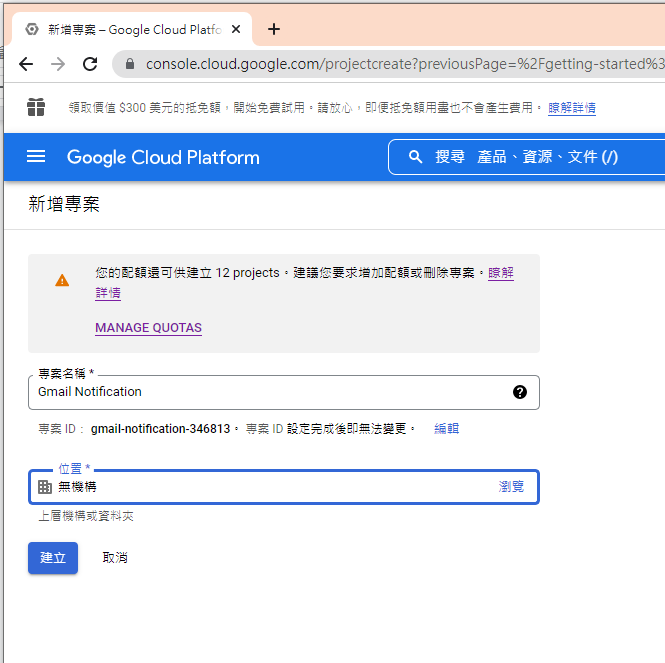
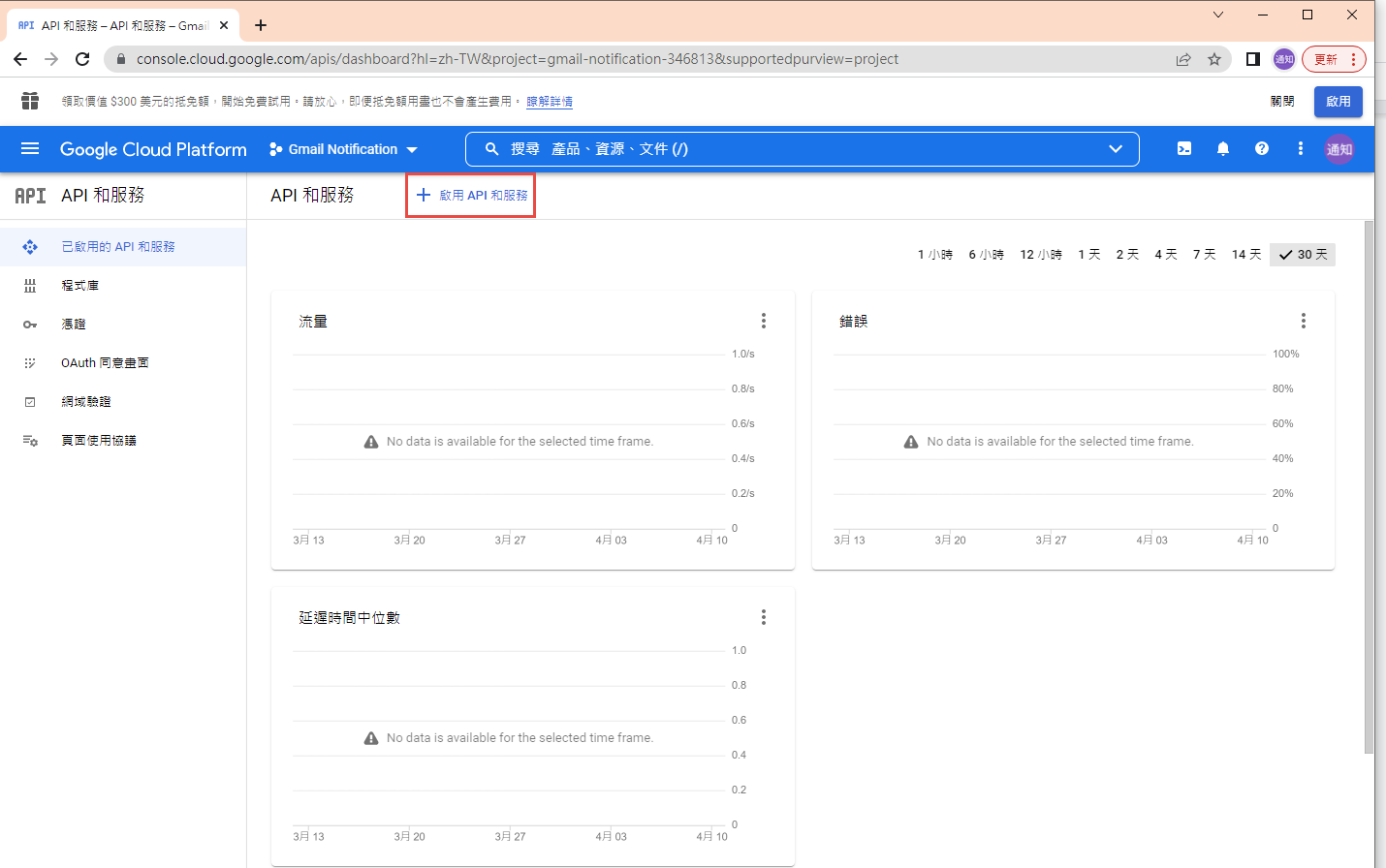
啟用 Gmail API
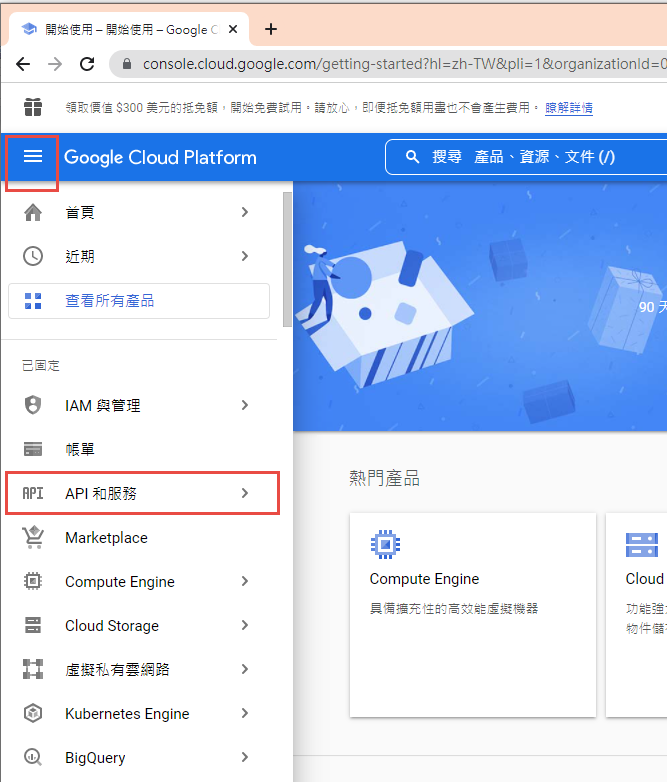
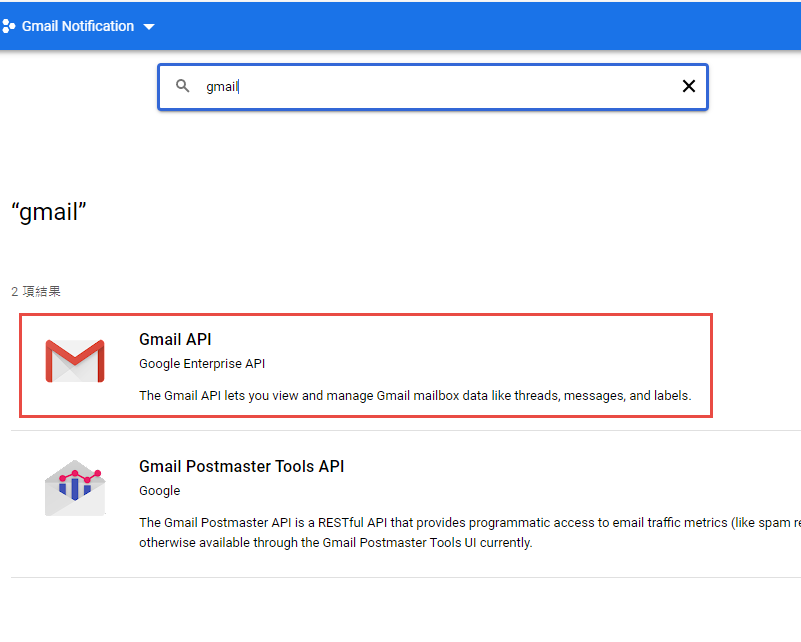
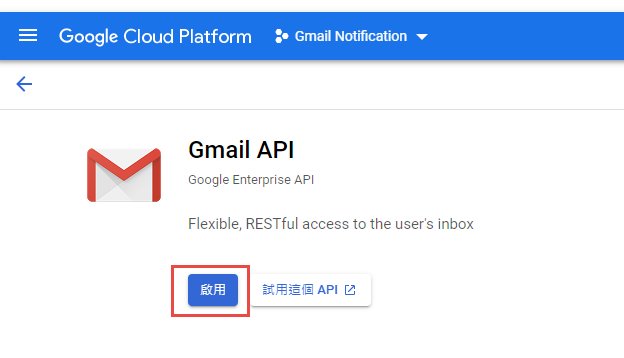
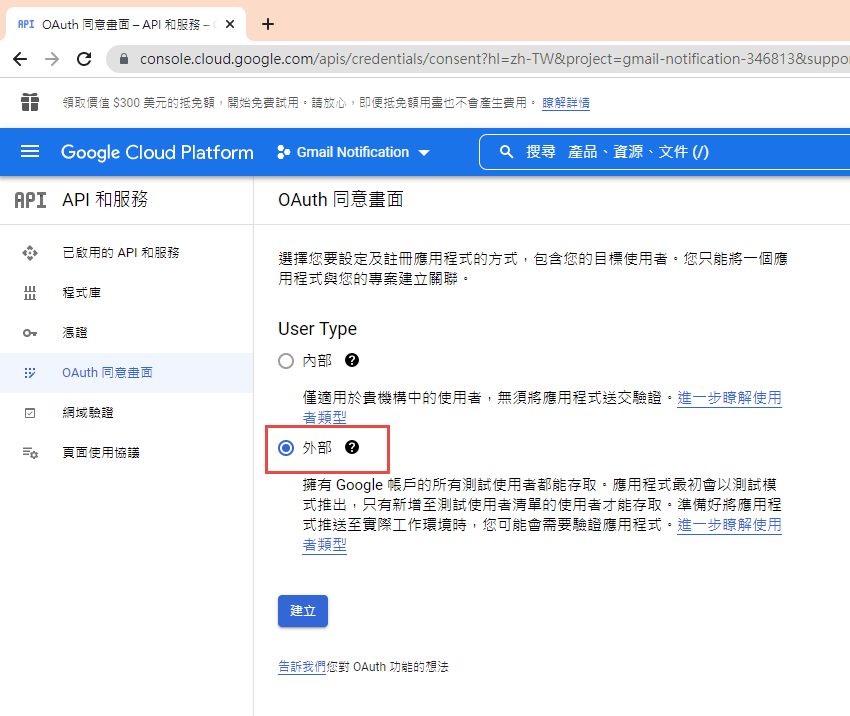
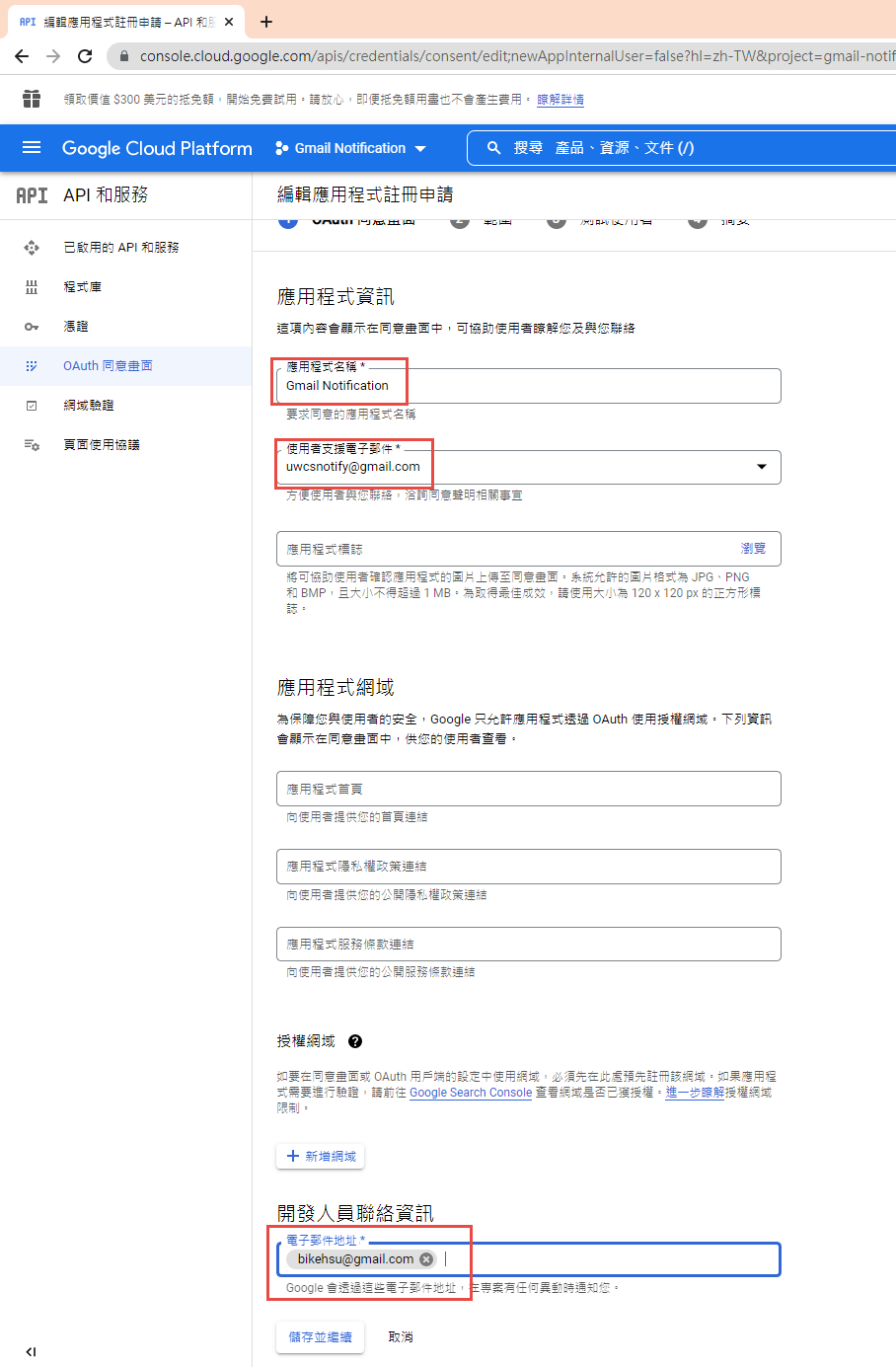
因為我們要透過 OAuth 取得使用者授權,所以要設定使用 OAuth 的同意畫面。
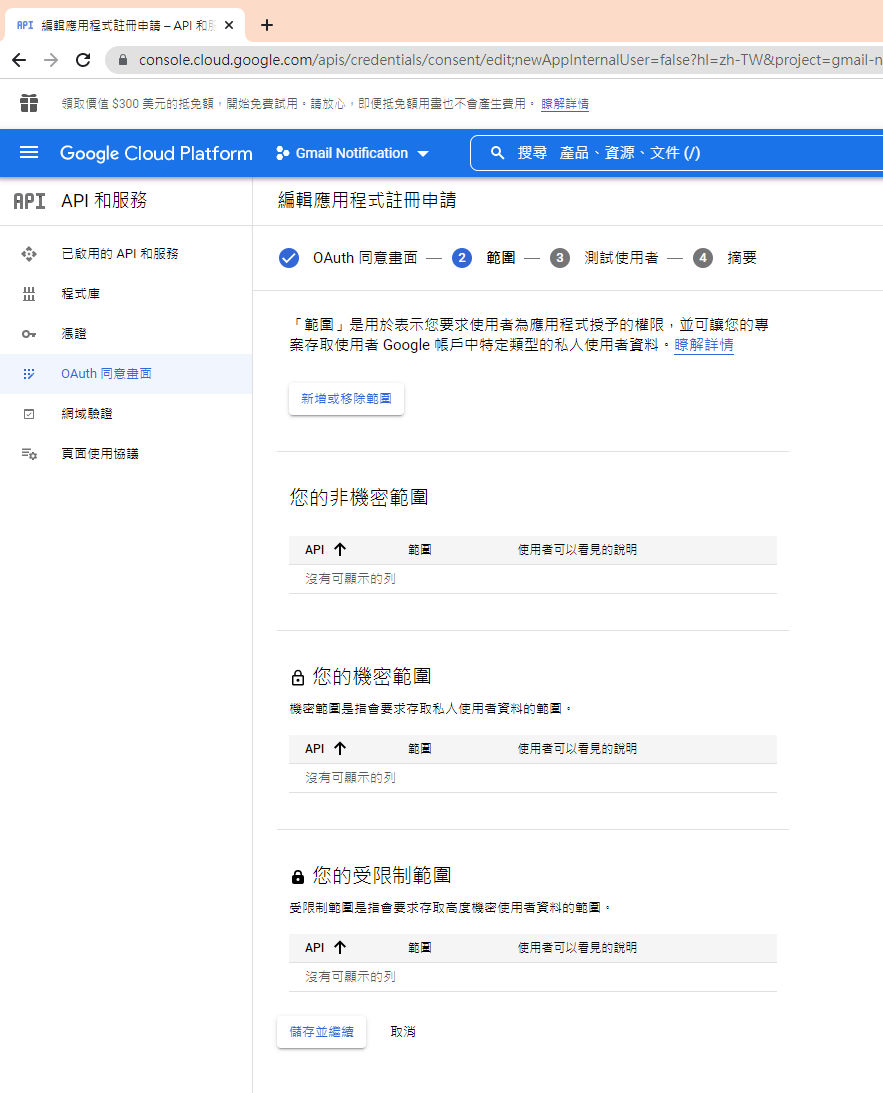
指定授權的範圍
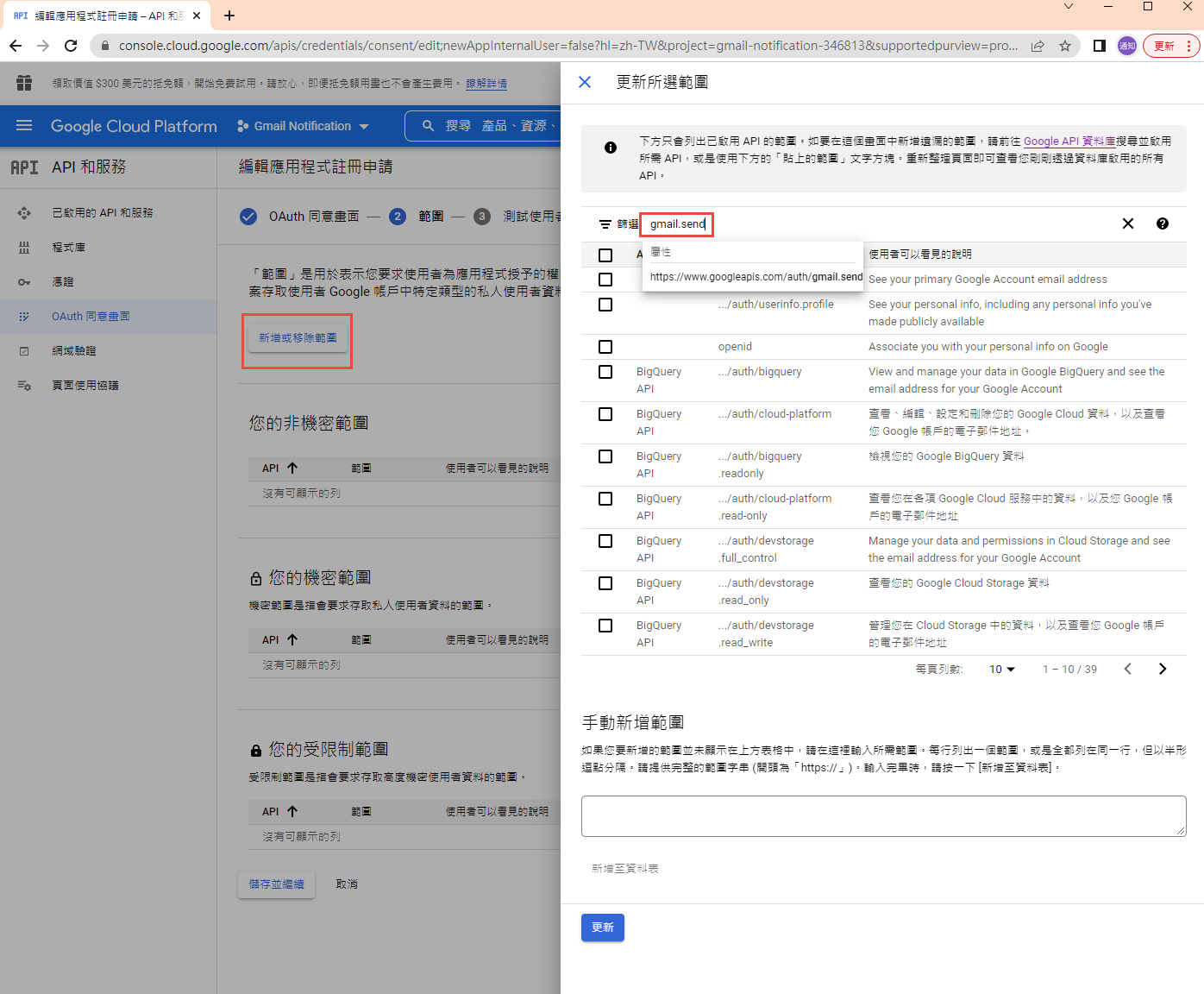
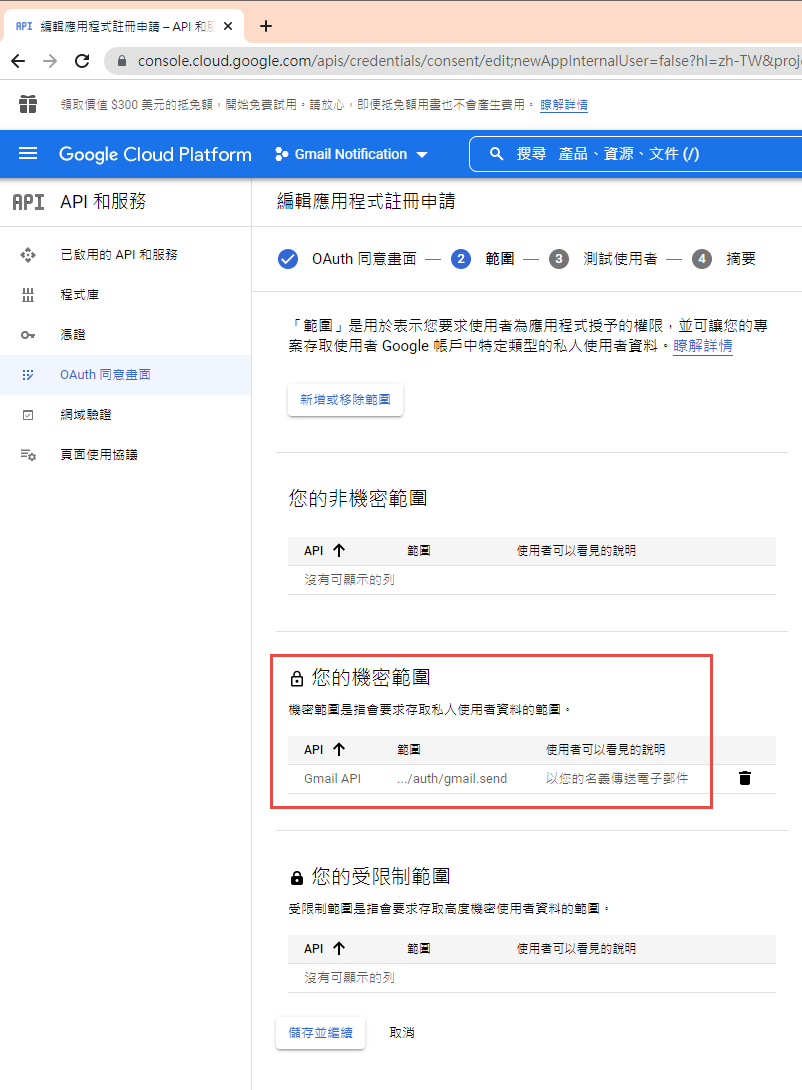
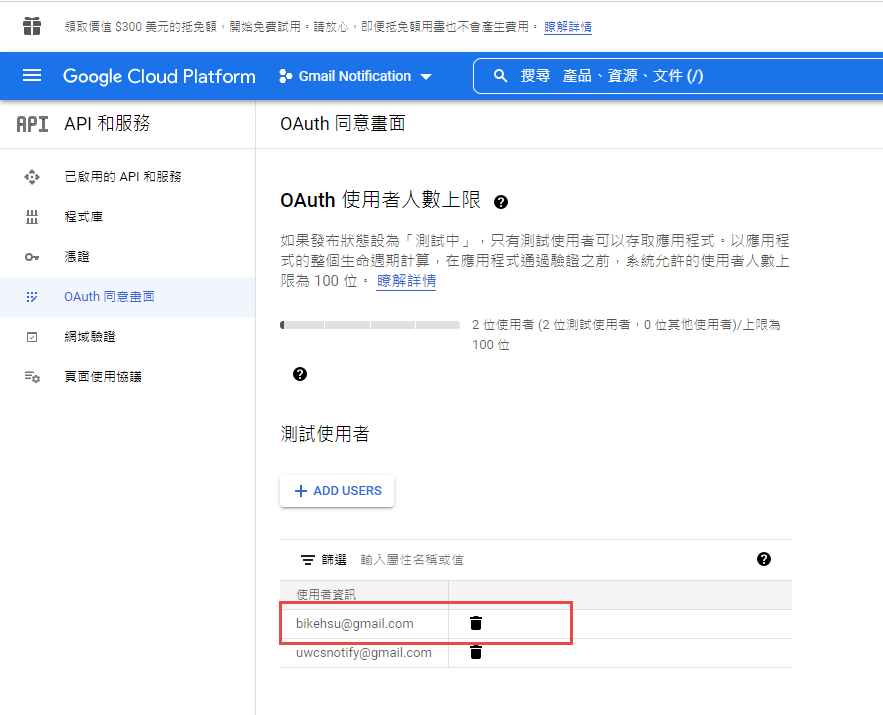
因為剛建立的專案,不會被公開,所以要指定測試使用者
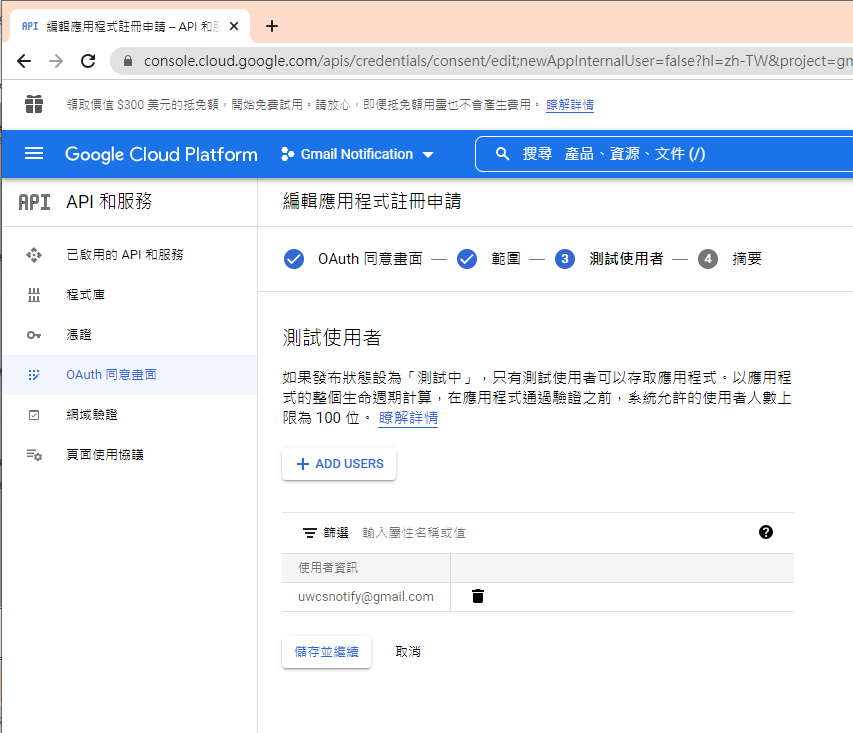
如果要給任意使用者,必需經過發布的流程,但準備工作有點麻煩,所以這次就不發布了。
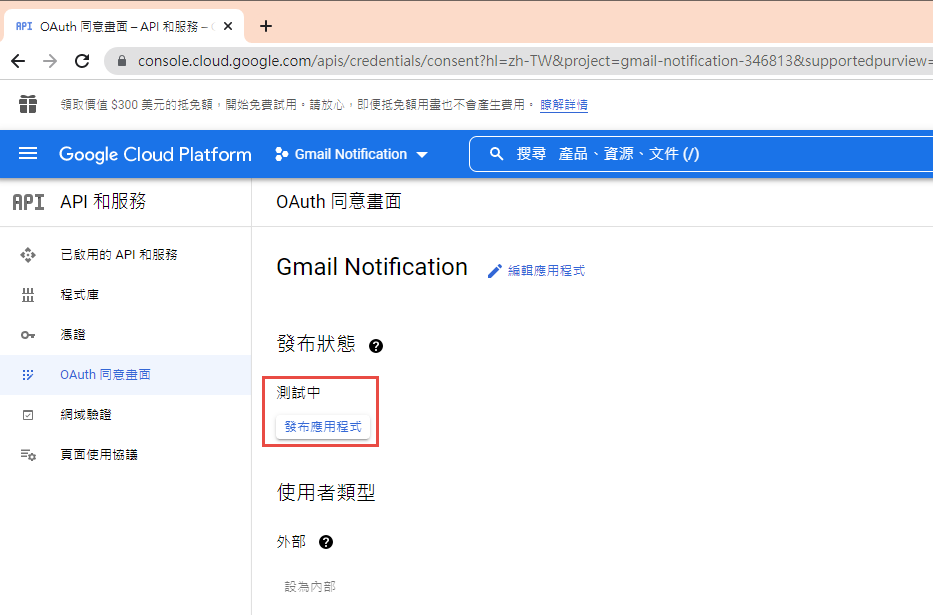
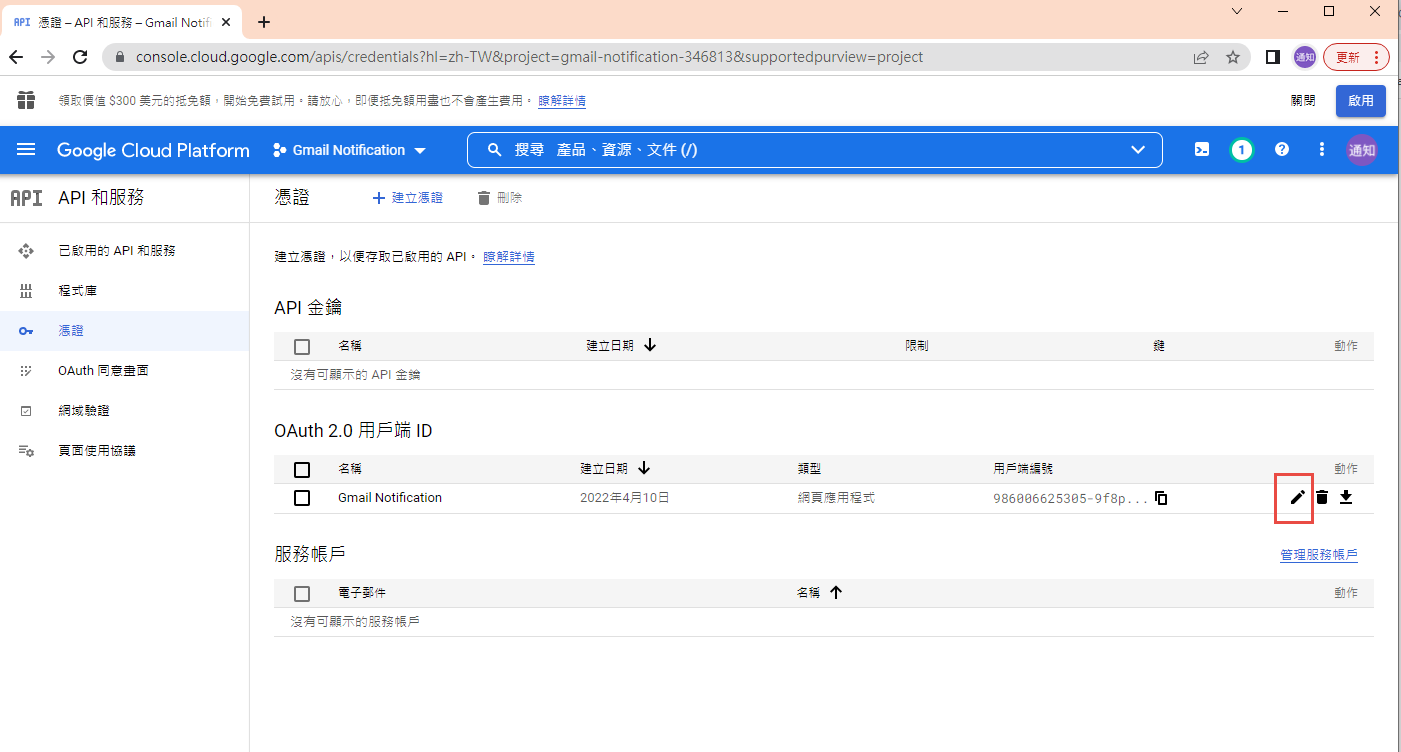
建立 OAuth 2.0 用戶端 ID 憑証
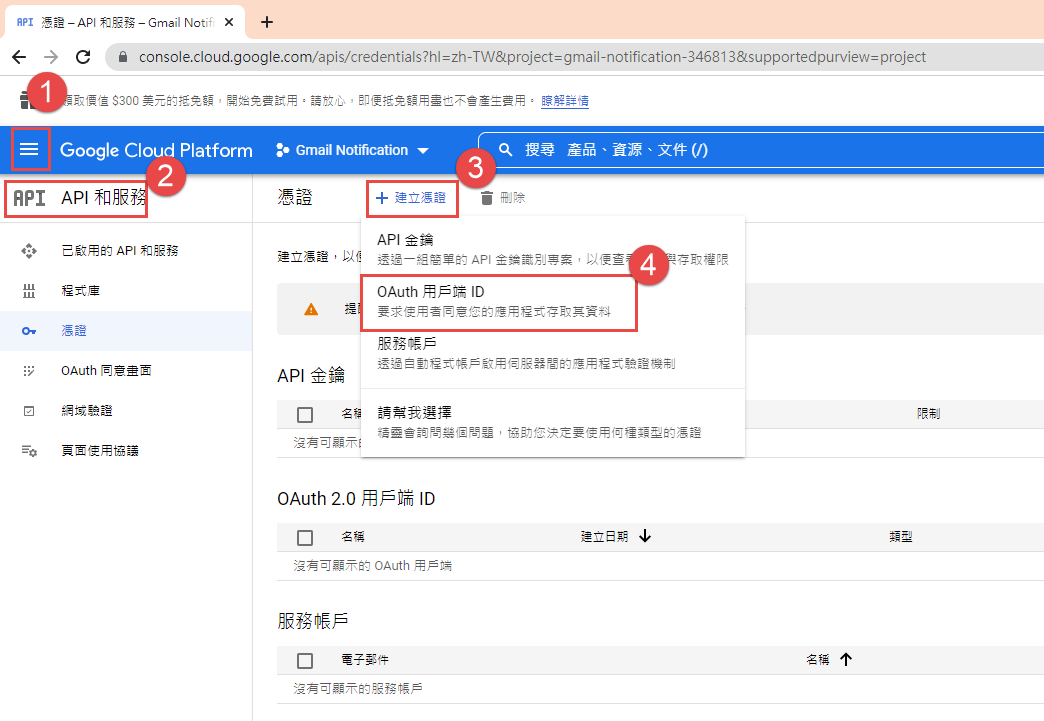
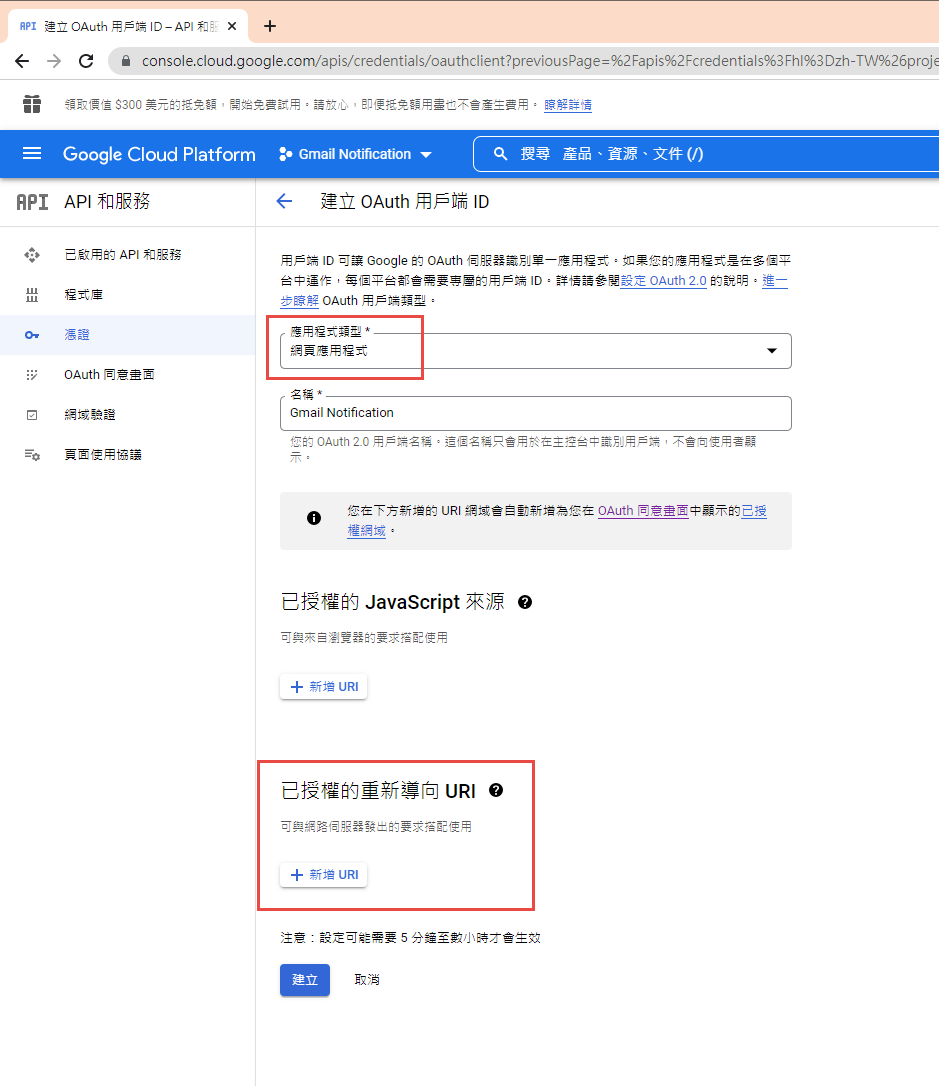
這裡除了名稱外,還有一個設定重導 Uri 的項目。現在不填寫,但稍後要回來補這個資料。
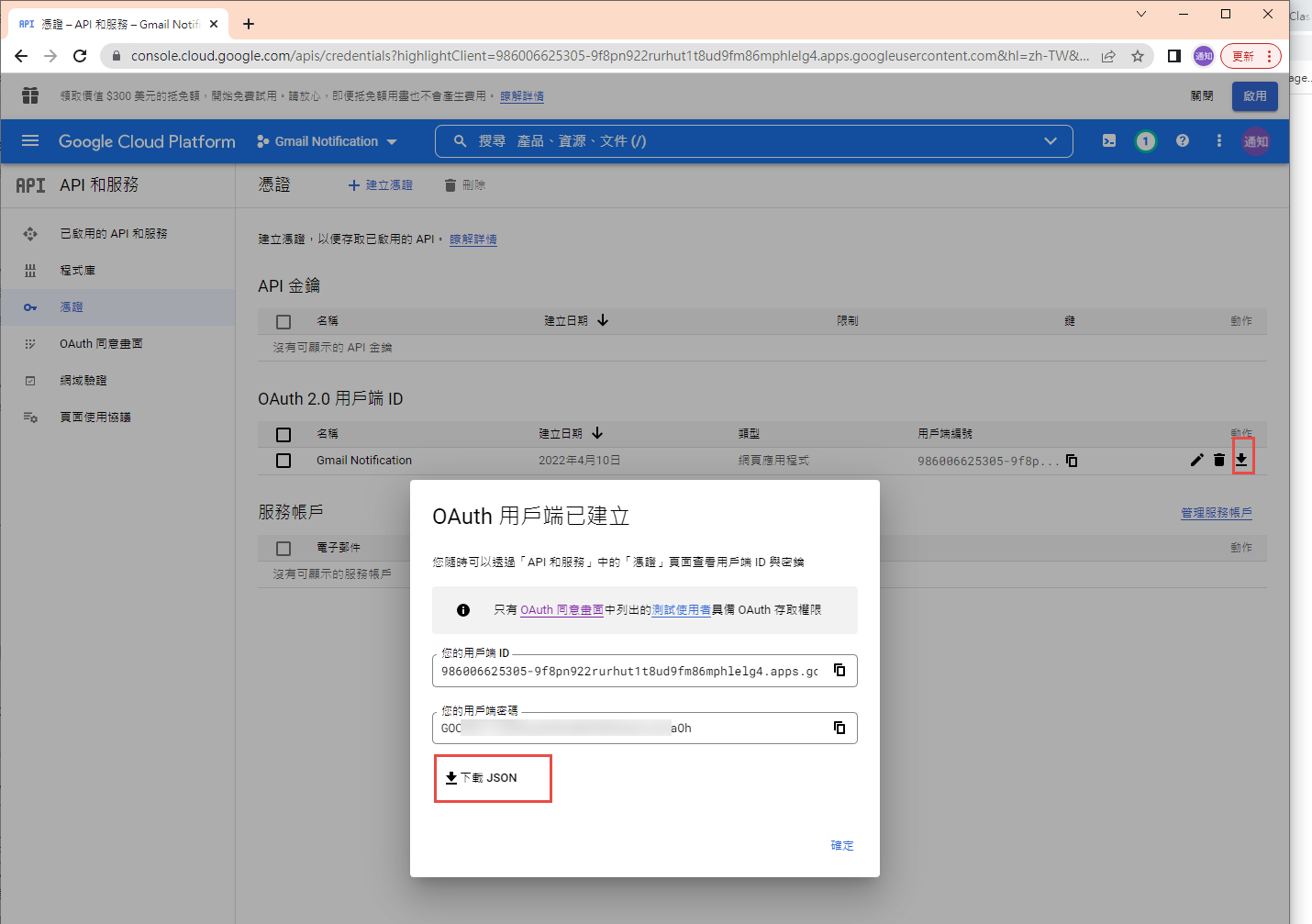
下載 json 之後,命名為 client_secret.json 保留後續使用。
再來就要建立專案了. 用 VS2022 建立一個新專案
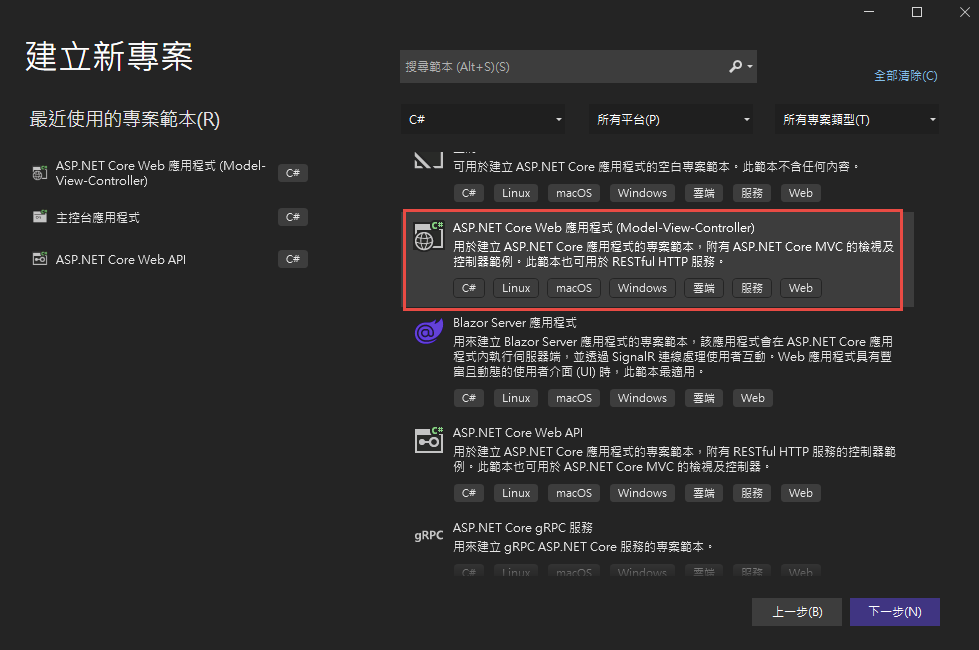
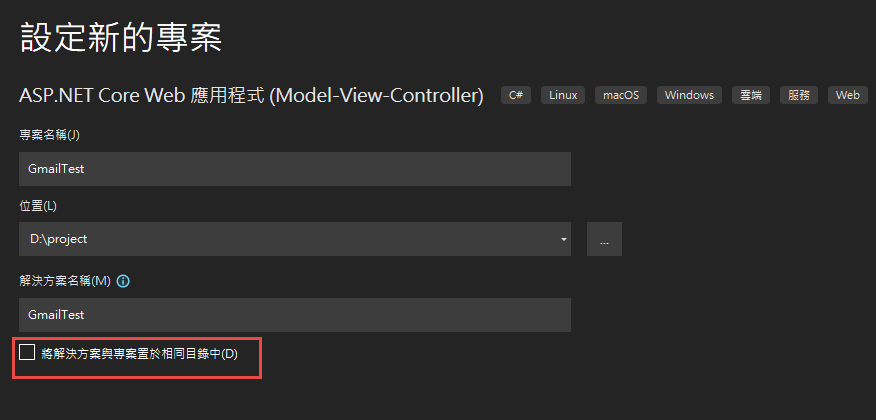
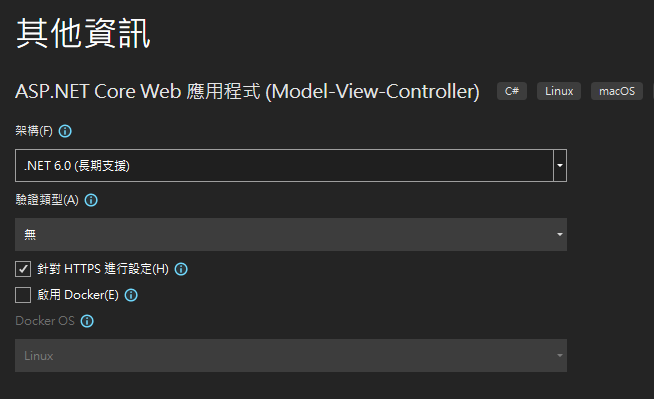
記錄網址, 本測試專案是 https://localhost:44340/ ,請依實際網址為準。
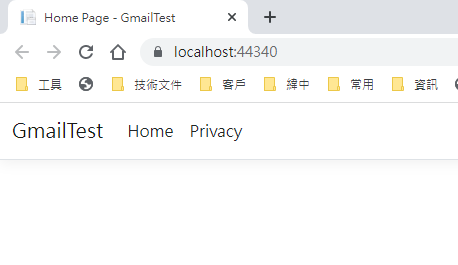
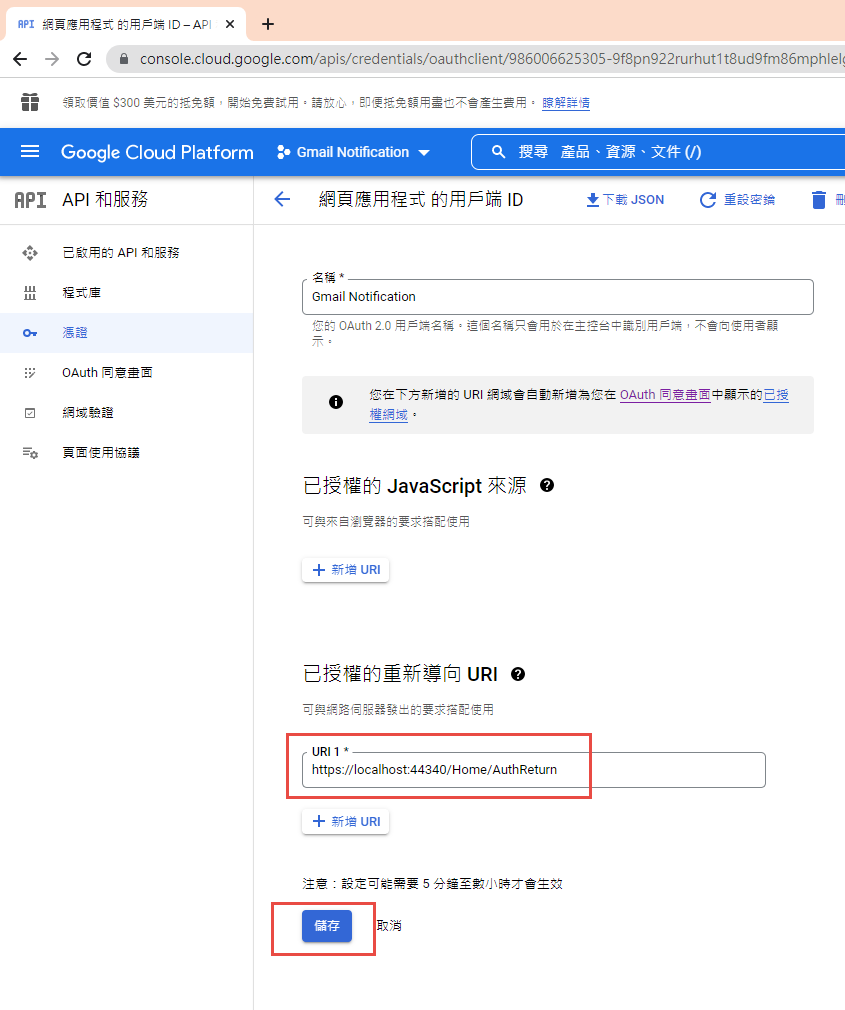
回到 OAuth 2.0 用戶端 ID 的設定頁. 在已授權的重新導向 URI 中填入 https://localhost:44340/Home/AuthReturn (填入的網址依實際專案的狀況,可能會有變化)
在 VS2022 中,使用 Nuget 安裝套件: (有漏的再麻煩和我說)
Google.Apis.Gmail.v1
Google.Apis.Auth
MimeKit (發送 gmail 時使用)
建立認証用的網址:
建立一個 Action, 用來取得認証用的網址:
執行結果:
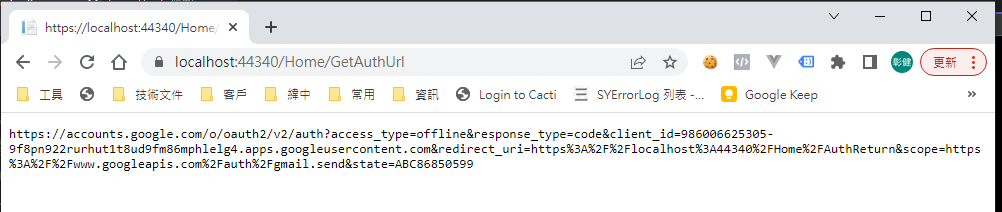
用 chrome 開啟產生的網址:
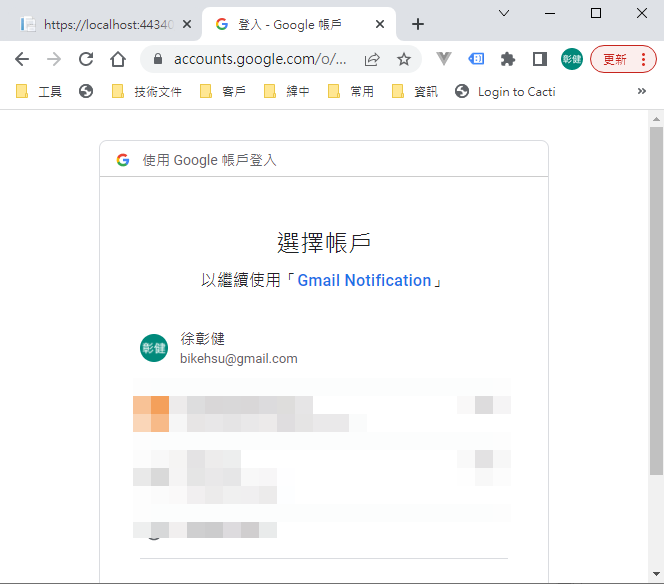
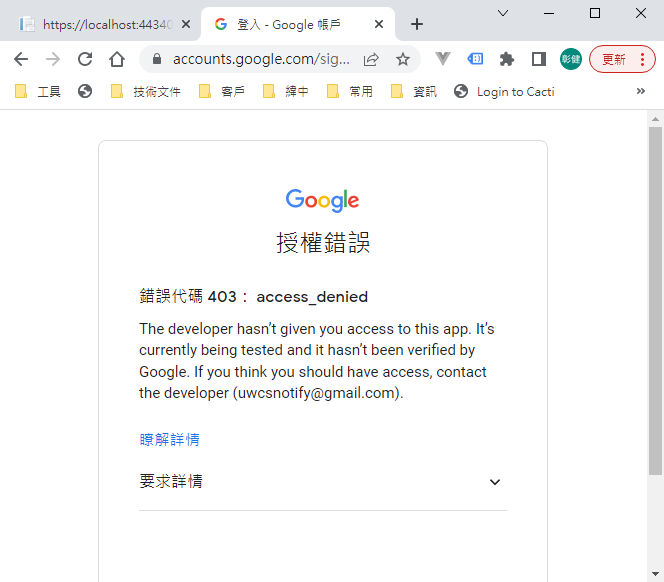
選取任一帳號,如果出現以下錯誤,請回到 "OAuth 同意畫面" 去新增測試使用者
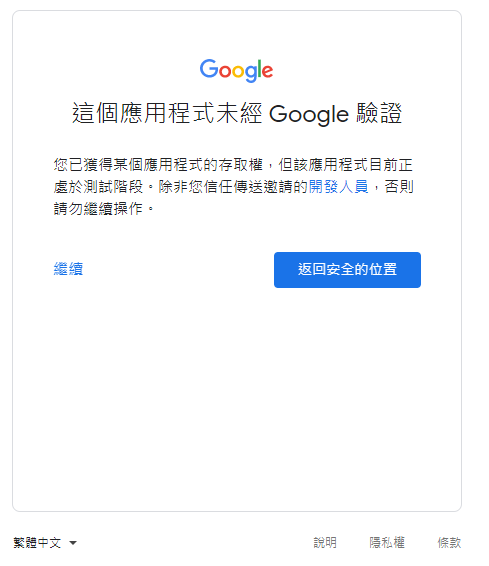
因為應用程式尚未發布,所以會看到警告,勇敢的繼續下去
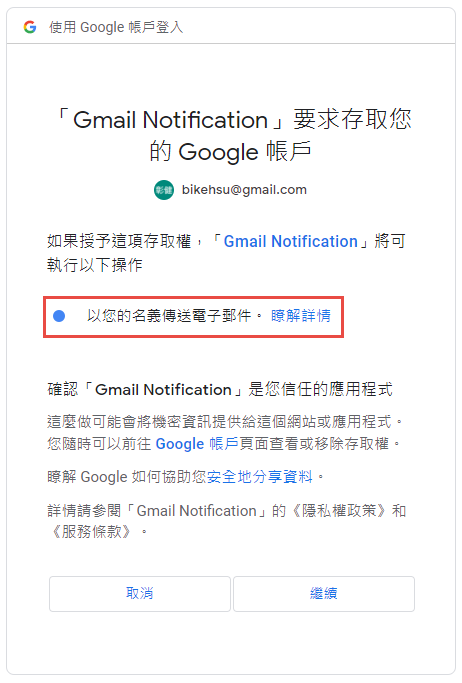
這裡會要求授權使用你的名義發送信件。(這是在程式中取得授權的項目 Scopes 中所指定的)
再繼續之後,會被重導至我們在 redirectUri 指定的網址。因為我們尚未完成,所以會看到錯誤,順便也可以看一下,會帶回哪一些參數。有 state, code, scope,共三個。
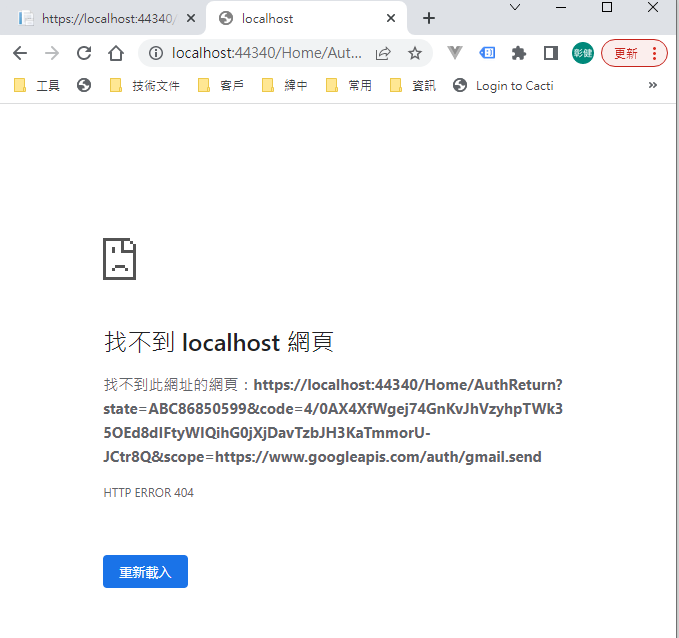
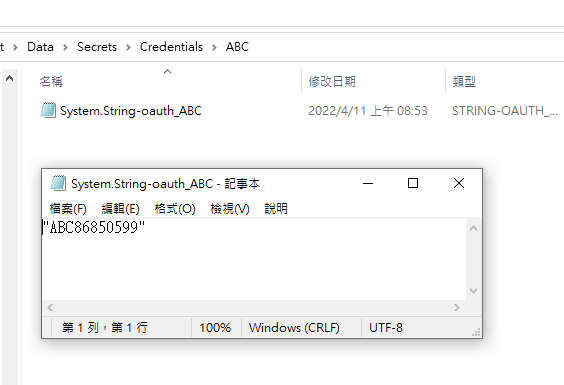
順便看一下,google 的套件會在 Credentials 的目錄下幫使用者建立一個目錄,在完成驗証前,會先放一個 System.String-oauth_XXX 的檔案,裡面的值和回傳的 state 是一樣的,這個應該是用來驗証回傳資料的。
接下來我們要新增 Action "AuthReturn" 如下:
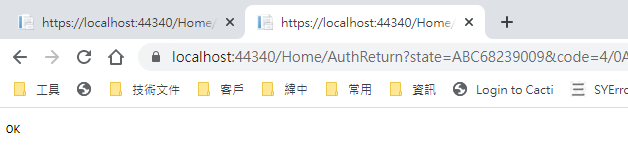
再跑一次上面的流程,最後回到 AuthReturn
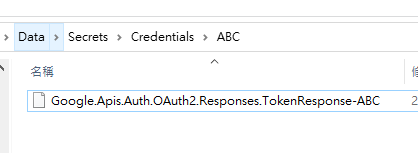
在 D:\project\GmailTest\Data\Secrets\Credentials\ABC 裡面會產生一個檔案: 這個就是我們的 token 了。
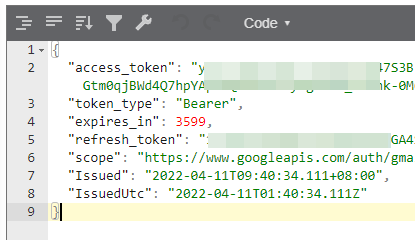
看一下裡面的內容, 有 access_token, refresh_token, scope 等等, 用途應該很好猜了.. 不知道各項目的目途也沒有關係。只要有這個 token 就可以了。
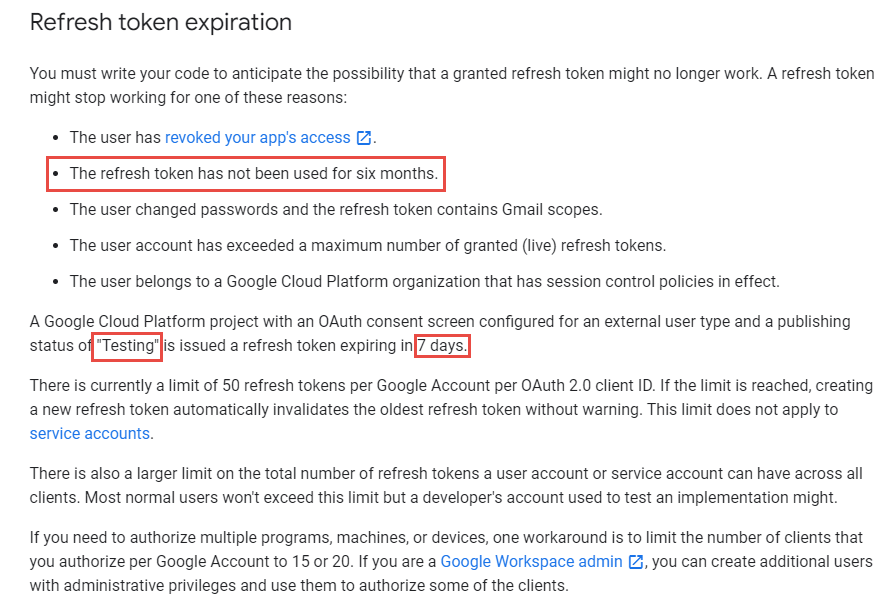
refresh_token 的效期請參考以下文件:
https://developers.google.com/identity/protocols/oauth2 。也可以參考下圖, 若是要用 gmail api 來發送通知信(例如連絡我們),紅色的地方是比較令人困擾的,例如 6 個月以上,沒有人留言,原來留下的 refresh_token 就失效了。使用者必需重新建立一個 refresh_token 。
最後來使用 gmail api 發送通知信, 直接看程式碼如下: 在這個過程中遇到最大的問題除了憑証問題之外,另一個問題是編碼。直到最後找到可以用 MimeKit 把 System.Net.Mail.MailMessage 編碼成 Gmail API 的格式才解決。程式碼如下:
收到的信件:
結論:
使用 Gmail API 最大的原因是要增加安全性,和舊的 smtp 不同的地方是,使用 gmail api 之後,客戶不需要提供 gmail 的帳號和密碼就可以讓系統使用 gmail 發送信件,不過由於 refresh_token 的效期問題,可能會造成無法發送通知信而沒有任何人發現的情況,整個實用性會變的很低。
另一個還沒有測試的部份是應用程的啟用。這個審核不知道會不很麻煩,不過可以而知的時,整個流程會花更多的時間。
取代的做法: 可能要改用 Amazon 的 SES 來寄信,而且為了避免每個小網站都要跑 SES 的建立流程,準備來寫一個 API 給各網站使用,可以發送簡單的通知信。
以上的程式碼可以在這裡下載: https://github.com/bikehsu/GmailTest
如果你的目的是要使用 Gmail Api 取代舊的 Gmail SMTP 來發送通知信,建議你先跳到最下方看一下結論。
如果你是想要看一下 Gmail API 和 Google API 憑証的使用方法,可以看一下這篇文章。
1. 在 google cloud platform 建立新的專案.
https://console.cloud.google.com/
啟用 Gmail API
因為我們要透過 OAuth 取得使用者授權,所以要設定使用 OAuth 的同意畫面。
指定授權的範圍
因為剛建立的專案,不會被公開,所以要指定測試使用者
如果要給任意使用者,必需經過發布的流程,但準備工作有點麻煩,所以這次就不發布了。
建立 OAuth 2.0 用戶端 ID 憑証
這裡除了名稱外,還有一個設定重導 Uri 的項目。現在不填寫,但稍後要回來補這個資料。
下載 json 之後,命名為 client_secret.json 保留後續使用。
再來就要建立專案了. 用 VS2022 建立一個新專案
記錄網址, 本測試專案是 https://localhost:44340/ ,請依實際網址為準。
回到 OAuth 2.0 用戶端 ID 的設定頁. 在已授權的重新導向 URI 中填入 https://localhost:44340/Home/AuthReturn (填入的網址依實際專案的狀況,可能會有變化)
在 VS2022 中,使用 Nuget 安裝套件: (有漏的再麻煩和我說)
Google.Apis.Gmail.v1
Google.Apis.Auth
MimeKit (發送 gmail 時使用)
建立認証用的網址:
建立一個 Action, 用來取得認証用的網址:
/// <summary>
/// 取得授權的項目
/// </summary>
static string[] Scopes = { GmailService.Scope.GmailSend };
// 和登入 google 的帳號無關
// 任意值,若未來有使用者認証,可使用使用者編號或登入帳號。
string Username = "ABC";
/// <summary>
/// 存放 client_secret 和 credential 的地方
/// </summary>
string SecretPath = @"D:\project\GmailTest\Data\Secrets";
/// <summary>
/// 認証完成後回傳的網址, 必需和 OAuth 2.0 Client Id 中填寫的 "已授權的重新導向 URI" 相同。
/// </summary>
string RedirectUri = $"https://localhost:44340/Home/AuthReturn";
/// <summary>
/// 取得認証用的網址
/// </summary>
/// <returns></returns>
public async Task<string> GetAuthUrl()
{
using (var stream = new FileStream(Path.Combine(SecretPath, "client_secret.json"), FileMode.Open, FileAccess.Read))
{
FileDataStore dataStore = null;
var credentialRoot = Path.Combine(SecretPath, "Credentials");
if (!Directory.Exists(credentialRoot))
{
Directory.CreateDirectory(credentialRoot);
}
//存放 credential 的地方,每個 username 會建立一個目錄。
string filePath = Path.Combine(credentialRoot, Username);
dataStore = new FileDataStore(filePath);
IAuthorizationCodeFlow flow = new GoogleAuthorizationCodeFlow(new GoogleAuthorizationCodeFlow.Initializer
{
ClientSecrets = GoogleClientSecrets.Load(stream).Secrets,
Scopes = Scopes,
DataStore = dataStore
});
var authResult = await new AuthorizationCodeWebApp(flow, RedirectUri, Username)
.AuthorizeAsync(Username, CancellationToken.None);
return authResult.RedirectUri;
}
}
執行結果:
用 chrome 開啟產生的網址:
選取任一帳號,如果出現以下錯誤,請回到 "OAuth 同意畫面" 去新增測試使用者
因為應用程式尚未發布,所以會看到警告,勇敢的繼續下去
這裡會要求授權使用你的名義發送信件。(這是在程式中取得授權的項目 Scopes 中所指定的)
再繼續之後,會被重導至我們在 redirectUri 指定的網址。因為我們尚未完成,所以會看到錯誤,順便也可以看一下,會帶回哪一些參數。有 state, code, scope,共三個。
順便看一下,google 的套件會在 Credentials 的目錄下幫使用者建立一個目錄,在完成驗証前,會先放一個 System.String-oauth_XXX 的檔案,裡面的值和回傳的 state 是一樣的,這個應該是用來驗証回傳資料的。
接下來我們要新增 Action "AuthReturn" 如下:
public async Task<string> AuthReturn(AuthorizationCodeResponseUrl authorizationCode)
{
string[] scopes = new[] { GmailService.Scope.GmailSend };
using (var stream = new FileStream(Path.Combine(SecretPath, "client_secret.json"), FileMode.Open, FileAccess.Read))
{
//確認 credential 的目錄已建立.
var credentialRoot = Path.Combine(SecretPath, "Credentials");
if (!Directory.Exists(credentialRoot))
{
Directory.CreateDirectory(credentialRoot);
}
//暫存憑証用目錄
string tempPath = Path.Combine(credentialRoot, authorizationCode.State);
IAuthorizationCodeFlow flow = new GoogleAuthorizationCodeFlow(
new GoogleAuthorizationCodeFlow.Initializer
{
ClientSecrets = GoogleClientSecrets.Load(stream).Secrets,
Scopes = scopes,
DataStore = new FileDataStore(tempPath)
});
//這個動作應該是要把 code 換成 token
await flow.ExchangeCodeForTokenAsync(Username, authorizationCode.Code, RedirectUri, CancellationToken.None).ConfigureAwait(false);
if (!string.IsNullOrWhiteSpace(authorizationCode.State))
{
string newPath = Path.Combine(credentialRoot, Username);
if (tempPath.ToLower() != newPath.ToLower())
{
if (Directory.Exists(newPath))
Directory.Delete(newPath, true);
Directory.Move(tempPath, newPath);
}
}
return "OK";
}
}
再跑一次上面的流程,最後回到 AuthReturn
在 D:\project\GmailTest\Data\Secrets\Credentials\ABC 裡面會產生一個檔案: 這個就是我們的 token 了。
看一下裡面的內容, 有 access_token, refresh_token, scope 等等, 用途應該很好猜了.. 不知道各項目的目途也沒有關係。只要有這個 token 就可以了。
refresh_token 的效期請參考以下文件:
https://developers.google.com/identity/protocols/oauth2 。也可以參考下圖, 若是要用 gmail api 來發送通知信(例如連絡我們),紅色的地方是比較令人困擾的,例如 6 個月以上,沒有人留言,原來留下的 refresh_token 就失效了。使用者必需重新建立一個 refresh_token 。
最後來使用 gmail api 發送通知信, 直接看程式碼如下: 在這個過程中遇到最大的問題除了憑証問題之外,另一個問題是編碼。直到最後找到可以用 MimeKit 把 System.Net.Mail.MailMessage 編碼成 Gmail API 的格式才解決。程式碼如下:
public async Task<bool> SendTestMail()
{
var service = await GetGmailService();
GmailMessage message = new GmailMessage();
message.Subject = "標題";
message.Body = $"<h1>內容</h1>";
message.FromAddress = "bikehsu@gmail.com";
message.IsHtml = true;
message.ToRecipients = "bikehsu@gmail.com";
message.Attachments = new List<Attachment>();
string filePath = @"C:\Users\bike\Pictures\Vegetable_pumpkin.jpg"; //要附加的檔案
Attachment attachment1 = new Attachment(filePath);
message.Attachments.Add(attachment1);
SendEmail(message, service);
Console.WriteLine("OK");
return true;
}
async Task<GmailService> GetGmailService()
{
UserCredential credential = null;
var credentialRoot = Path.Combine(SecretPath, "Credentials");
if (!Directory.Exists(credentialRoot))
{
Directory.CreateDirectory(credentialRoot);
}
string filePath = Path.Combine(credentialRoot, Username);
using (var stream = new FileStream(Path.Combine(SecretPath, "client_secret.json"), FileMode.Open, FileAccess.Read))
{
credential = await GoogleWebAuthorizationBroker.AuthorizeAsync(
GoogleClientSecrets.Load(stream).Secrets,
Scopes,
Username,
CancellationToken.None,
new FileDataStore(filePath));
}
var service = new GmailService(new BaseClientService.Initializer()
{
HttpClientInitializer = credential,
ApplicationName = "Send Mail",
});
return service;
}
public class GmailMessage
{
public string FromAddress { get; set; }
public string ToRecipients { get; set; }
public string Subject { get; set; }
public string Body { get; set; }
public bool IsHtml { get; set; }
public List<System.Net.Mail.Attachment> Attachments { get; set; }
}
public static void SendEmail(GmailMessage email, GmailService service)
{
var mailMessage = new System.Net.Mail.MailMessage();
mailMessage.From = new System.Net.Mail.MailAddress(email.FromAddress);
mailMessage.To.Add(email.ToRecipients);
mailMessage.ReplyToList.Add(email.FromAddress);
mailMessage.Subject = email.Subject;
mailMessage.Body = email.Body;
mailMessage.IsBodyHtml = email.IsHtml;
if (email.Attachments != null)
{
foreach (System.Net.Mail.Attachment attachment in email.Attachments)
{
mailMessage.Attachments.Add(attachment);
}
}
var mimeMessage = MimeKit.MimeMessage.CreateFromMailMessage(mailMessage);
var gmailMessage = new Google.Apis.Gmail.v1.Data.Message
{
Raw = Encode(mimeMessage)
};
Google.Apis.Gmail.v1.UsersResource.MessagesResource.SendRequest request = service.Users.Messages.Send(gmailMessage, "me");
request.Execute();
}
public static string Encode(MimeMessage mimeMessage)
{
using (MemoryStream ms = new MemoryStream())
{
mimeMessage.WriteTo(ms);
return Convert.ToBase64String(ms.GetBuffer())
.TrimEnd('=')
.Replace('+', '-')
.Replace('/', '_');
}
}
收到的信件:
結論:
使用 Gmail API 最大的原因是要增加安全性,和舊的 smtp 不同的地方是,使用 gmail api 之後,客戶不需要提供 gmail 的帳號和密碼就可以讓系統使用 gmail 發送信件,不過由於 refresh_token 的效期問題,可能會造成無法發送通知信而沒有任何人發現的情況,整個實用性會變的很低。
另一個還沒有測試的部份是應用程的啟用。這個審核不知道會不很麻煩,不過可以而知的時,整個流程會花更多的時間。
取代的做法: 可能要改用 Amazon 的 SES 來寄信,而且為了避免每個小網站都要跑 SES 的建立流程,準備來寫一個 API 給各網站使用,可以發送簡單的通知信。
以上的程式碼可以在這裡下載: https://github.com/bikehsu/GmailTest
Bike, 2022/4/10 下午 09:31:15
感覺上, Oracle 的 table space 和 MS-SQL 的 DB 是一樣的。都是用來指定實體檔案。
google 到的範例居然有小 bug, 記錄一個修正版如下:
CREATE TABLESPACE TABPE_SPACE_NAME
DATAFILE 'TABPE_SPACE_NAME.dbf'
SIZE 1m
AUTOEXTEND ON;
完成之後,可以列出所有 table space:
SELECT A.TABLESPACE_NAME, A.FILE_NAME,
ROUND(B.FREE_GB,2) AS FREE_GB ,
ROUND(A.TOTAL_GB - b.FREE_GB) AS USED_GB ,
ROUND(A.TOTAL_GB,2) AS TOTAL_GB ,
ROUND(((A.TOTAL_GB - B.FREE_GB)/ A.TOTAL_GB )*100,2) AS USED_PERCENT,
ROUND((B.FREE_GB/ A.TOTAL_GB )*100,2) AS FREE_PERCENT
FROM
(
SELECT TABLESPACE_NAME, FILE_NAME,
SUM(BYTES)/ (1024*1024*1024) AS TOTAL_GB
FROM DBA_DATA_FILES
-- WHERE TABLESPACE_NAME='My_TableSpace_Name'
GROUP BY TABLESPACE_NAME, FILE_NAME
)A,
(
SELECT TABLESPACE_NAME,
SUM(BYTES) / (1024*1024*1024) AS FREE_GB
FROM DBA_FREE_SPACE
-- WHERE TABLESPACE_NAME='My_TableSpace_Name'
GROUP BY TABLESPACE_NAME
) B
WHERE A.TABLESPACE_NAME= B.TABLESPACE_NAME ;
google 到的範例居然有小 bug, 記錄一個修正版如下:
CREATE TABLESPACE TABPE_SPACE_NAME
DATAFILE 'TABPE_SPACE_NAME.dbf'
SIZE 1m
AUTOEXTEND ON;
完成之後,可以列出所有 table space:
SELECT A.TABLESPACE_NAME, A.FILE_NAME,
ROUND(B.FREE_GB,2) AS FREE_GB ,
ROUND(A.TOTAL_GB - b.FREE_GB) AS USED_GB ,
ROUND(A.TOTAL_GB,2) AS TOTAL_GB ,
ROUND(((A.TOTAL_GB - B.FREE_GB)/ A.TOTAL_GB )*100,2) AS USED_PERCENT,
ROUND((B.FREE_GB/ A.TOTAL_GB )*100,2) AS FREE_PERCENT
FROM
(
SELECT TABLESPACE_NAME, FILE_NAME,
SUM(BYTES)/ (1024*1024*1024) AS TOTAL_GB
FROM DBA_DATA_FILES
-- WHERE TABLESPACE_NAME='My_TableSpace_Name'
GROUP BY TABLESPACE_NAME, FILE_NAME
)A,
(
SELECT TABLESPACE_NAME,
SUM(BYTES) / (1024*1024*1024) AS FREE_GB
FROM DBA_FREE_SPACE
-- WHERE TABLESPACE_NAME='My_TableSpace_Name'
GROUP BY TABLESPACE_NAME
) B
WHERE A.TABLESPACE_NAME= B.TABLESPACE_NAME ;
Bike, 2022/4/6 上午 08:35:54
已經有資料的資料庫無法更改。
開啟 sqlplus
用 sys 登入 XPEDB1 指定為SYSDBA 的身份
--sqlplus SYS/password@localhost/XEPDB1 as SYSDBA
sqlplus / as SYSDBA
--修改 NLS_CHARACTERSET to ZHT16MSWIN950
shutdown immediate;
STARTUP MOUNT;
ALTER SESSION SET SQL_TRACE=TRUE;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
ALTER DATABASE OPEN;
ALTER DATABASE CHARACTER SET INTERNAL_USE ZHT16MSWIN950;
ALTER SESSION SET SQL_TRACE=FALSE;
shutdown immediate;
STARTUP;
查詢 nvarchar 的欄位
select owner, table_name, column_name
from dba_tab_columns
where (data_type = 'NCHAR' or
data_type = 'NVARCHAR2' or
data_type = 'NCLOB') and
owner != 'SYS' and
owner != 'SYSTEM';
要 truncate 兩個 table:
truncate table SYS.RADM_FPTM_LOB$;
truncate table SYS.RADM_FPTM$ ;
執行以下指令
修改 System 的 NLS_NCHAR_CHARACTERSET:
shutdown immediate;
STARTUP MOUNT;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0 SCOPE = MEMORY;
ALTER SYSTEM SET AQ_TM_PROCESSES=0 SCOPE = MEMORY;
ALTER DATABASE OPEN;
ALTER DATABASE NATIONAL CHARACTER SET UTF8;
SHUTDOWN IMMEDIATE;
STARTUP;
要修特定 PDB 的 NLS_NCHAR_CHARACTERSET:
alter session set container=cdb$root;
show pdbs;
alter pluggable database XEPDB1 close immediate;
alter pluggable database XEPDB1 open read write restricted;
alter session set container=XEPDB1;
truncate table SYS.RADM_FPTM_LOB$;
truncate table SYS.RADM_FPTM$;
ALTER DATABASE NATIONAL CHARACTER SET UTF8;
ALTER PLUGGABLE DATABASE XEPDB1 CLOSE IMMEDIATE;
ALTER PLUGGABLE DATABASE XEPDB1 OPEN;
select * from database_properties where PROPERTY_NAME in ('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET');
開啟 sqlplus
用 sys 登入 XPEDB1 指定為SYSDBA 的身份
--sqlplus SYS/password@localhost/XEPDB1 as SYSDBA
sqlplus / as SYSDBA
--修改 NLS_CHARACTERSET to ZHT16MSWIN950
shutdown immediate;
STARTUP MOUNT;
ALTER SESSION SET SQL_TRACE=TRUE;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
ALTER DATABASE OPEN;
ALTER DATABASE CHARACTER SET INTERNAL_USE ZHT16MSWIN950;
ALTER SESSION SET SQL_TRACE=FALSE;
shutdown immediate;
STARTUP;
查詢 nvarchar 的欄位
select owner, table_name, column_name
from dba_tab_columns
where (data_type = 'NCHAR' or
data_type = 'NVARCHAR2' or
data_type = 'NCLOB') and
owner != 'SYS' and
owner != 'SYSTEM';
要 truncate 兩個 table:
truncate table SYS.RADM_FPTM_LOB$;
truncate table SYS.RADM_FPTM$ ;
執行以下指令
修改 System 的 NLS_NCHAR_CHARACTERSET:
shutdown immediate;
STARTUP MOUNT;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0 SCOPE = MEMORY;
ALTER SYSTEM SET AQ_TM_PROCESSES=0 SCOPE = MEMORY;
ALTER DATABASE OPEN;
ALTER DATABASE NATIONAL CHARACTER SET UTF8;
SHUTDOWN IMMEDIATE;
STARTUP;
要修特定 PDB 的 NLS_NCHAR_CHARACTERSET:
alter session set container=cdb$root;
show pdbs;
alter pluggable database XEPDB1 close immediate;
alter pluggable database XEPDB1 open read write restricted;
alter session set container=XEPDB1;
truncate table SYS.RADM_FPTM_LOB$;
truncate table SYS.RADM_FPTM$;
ALTER DATABASE NATIONAL CHARACTER SET UTF8;
ALTER PLUGGABLE DATABASE XEPDB1 CLOSE IMMEDIATE;
ALTER PLUGGABLE DATABASE XEPDB1 OPEN;
select * from database_properties where PROPERTY_NAME in ('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET');
Bike, 2022/4/1 下午 05:31:17
首先尋找出一支欲調效的Table或Query
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
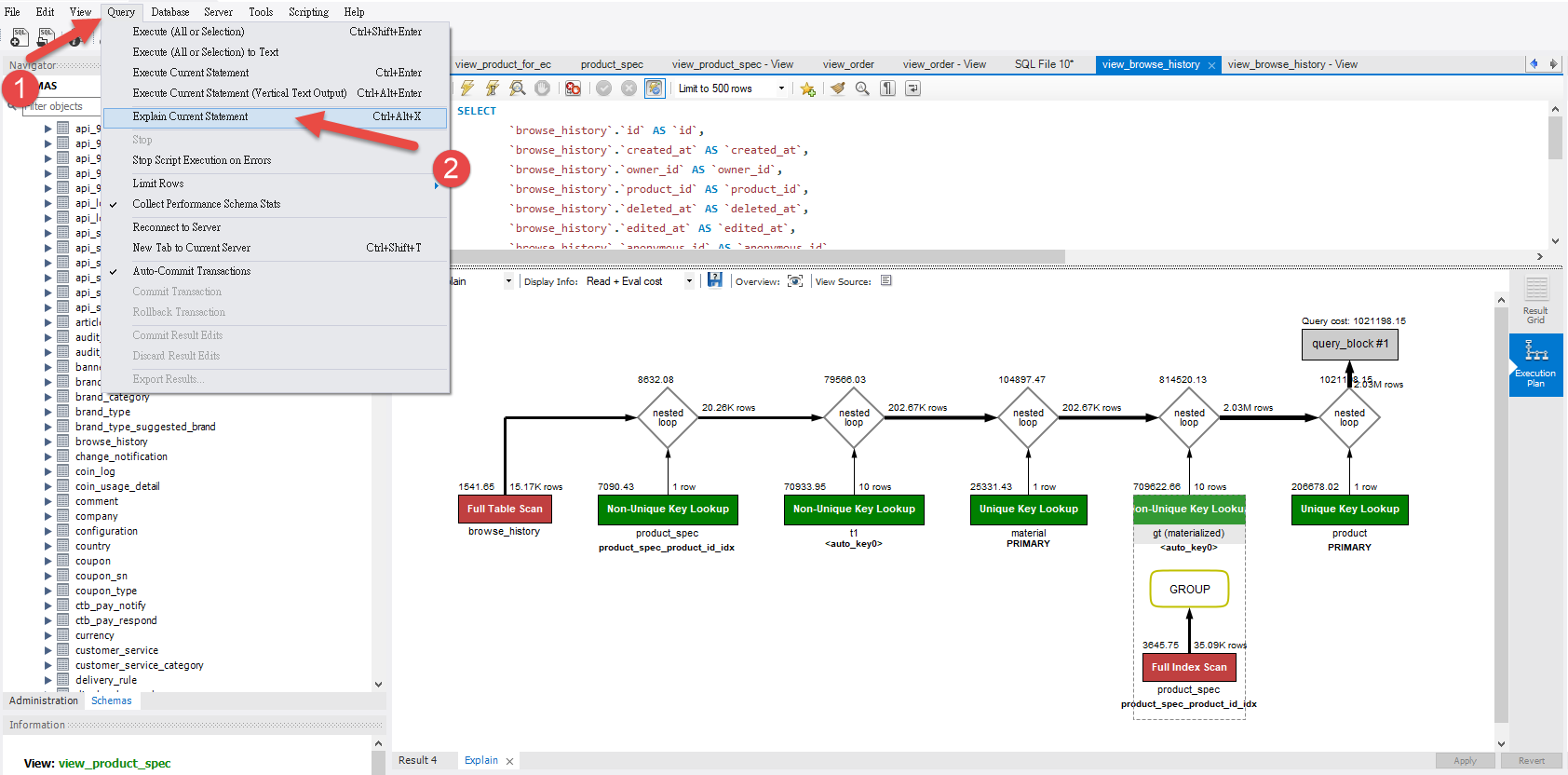
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
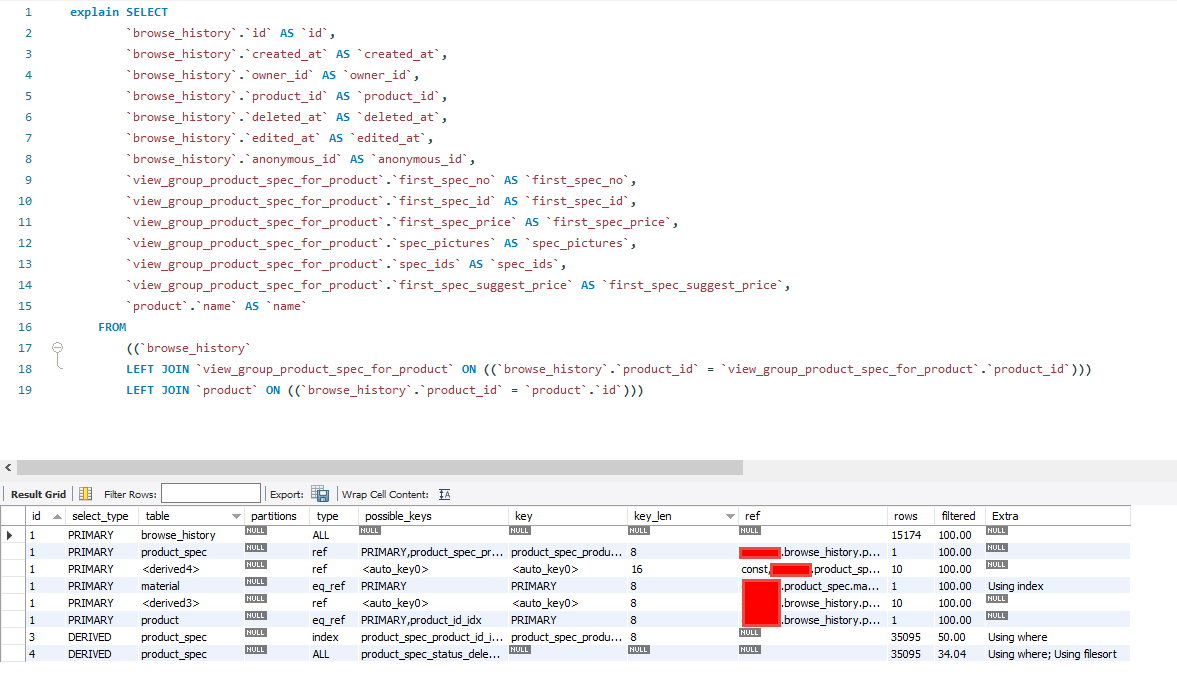
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
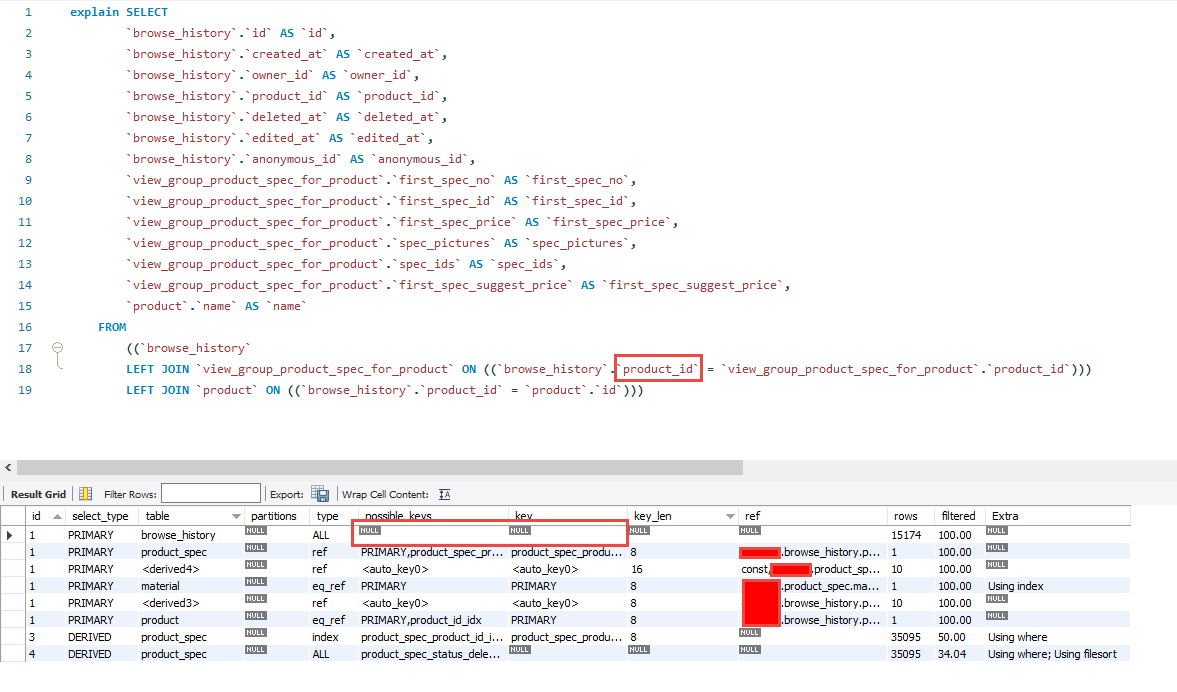
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
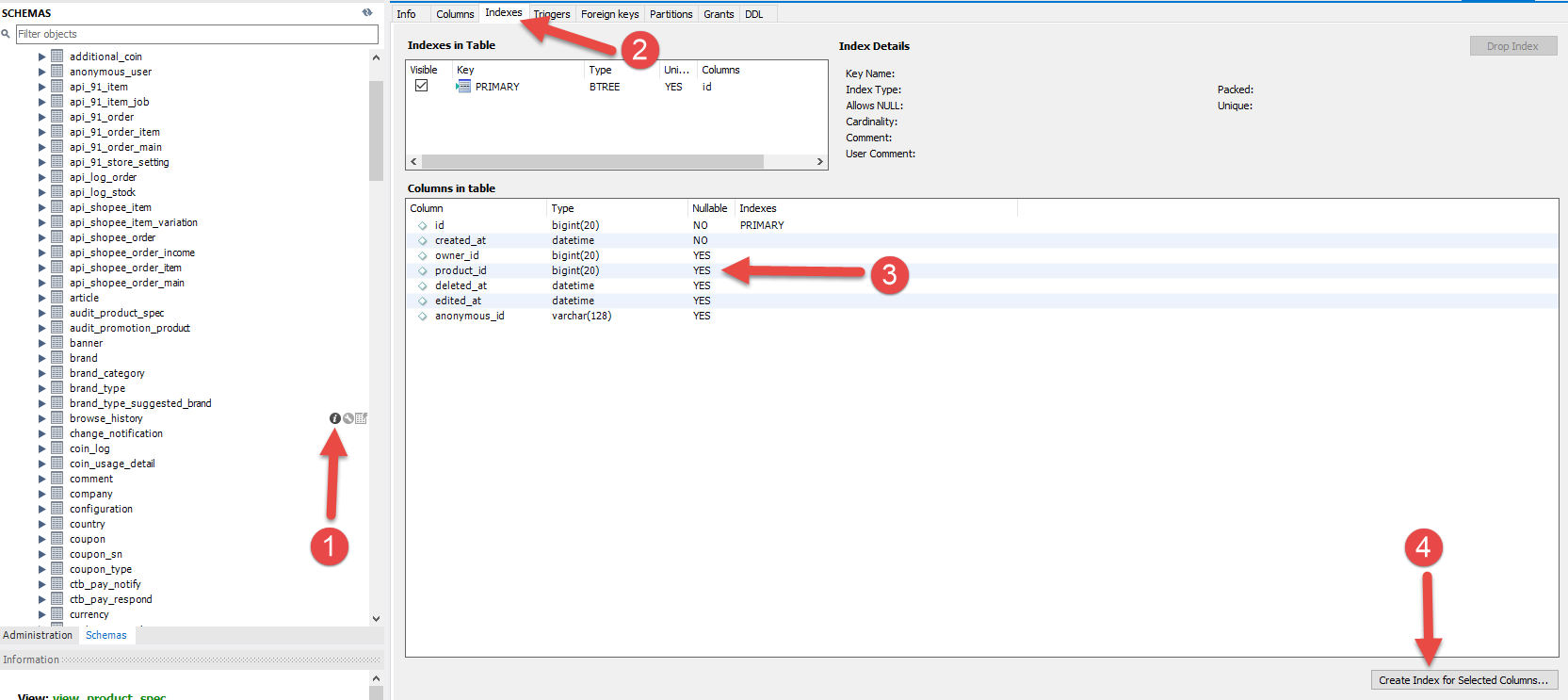
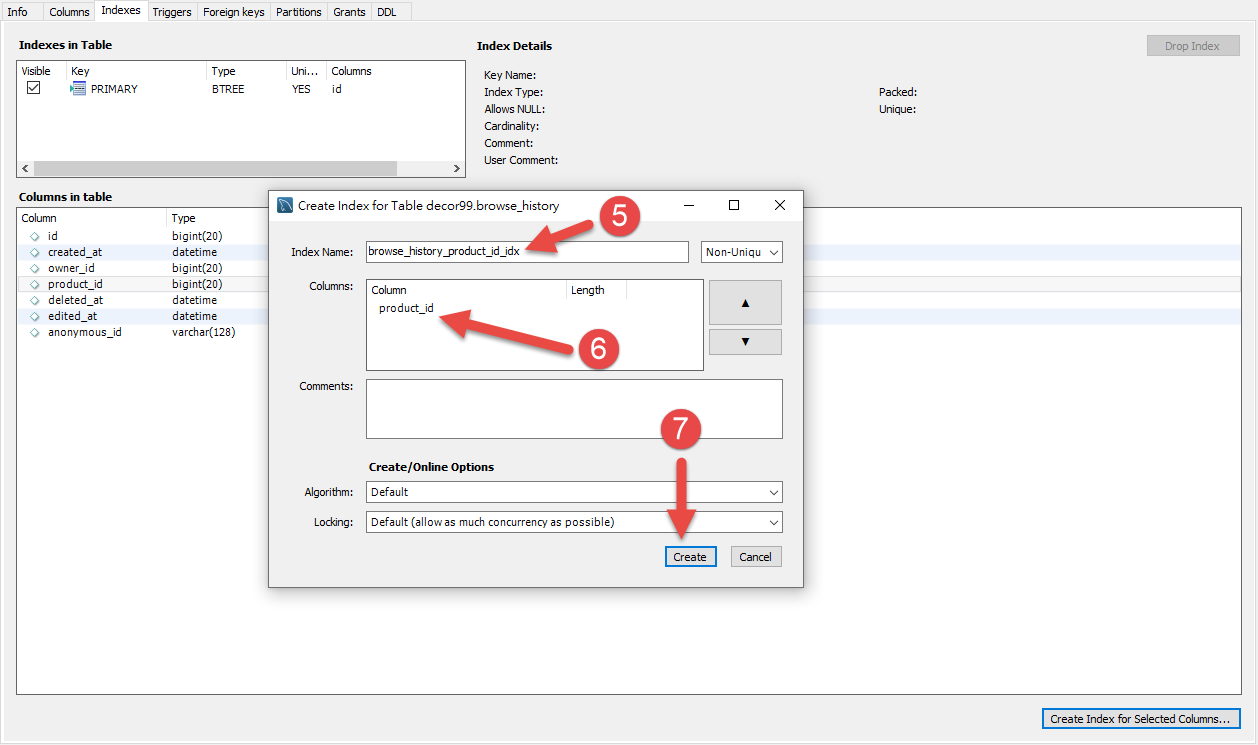
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
再來我們可以先使用左上方工具列 'Query' 內的 Explain Current Statement
便可以得到如以下的連結表
由圖中可以清楚的看見每一段Query後的資料量,並發現有數張表單是呈現紅色 'Full Table Scan'
,這代表該段Query對這張表單的每一行欄位都做了掃描。
再來我們在我們的Query前方加上 'EXPLAIN' 並執行
便得到了該段Query所關聯的表單與其詳細資訊
其中針對EXPLAIN的欄位說明如下:
table:關連到的資料表(Table)會顯示在此。
type:顯示使用了何種類型。從最優至最差的類型為const、eq_reg、ref、range、indexhe、ALL。
possible_keys:顯示可能使用到的索引。此為從WHERE語法中選擇一個適合的欄位名稱。
key:實際使用到的索引。如果為NULL,則是沒有使用索引。
key_len:使用索引的長度。長度越短 準確性越高。
ref:顯示那一列的索引被使用。一般是一個常數(const)。
rows:MySQL用來返回資料的筆數。
Extra:MySQL用來解析額外的查詢訊息。如果此欄位的值為:Using temporary和Using filesort,表示MySQL無法使用索引。
Extra為MySQL用來解析額外的查詢訊息,其中欄位值所代表的意義如下:
Distinct:當MySQL找到相關連的資料時,就不再搜尋。
Not exists:MySQL優化 LEFT JOIN,一旦找到符合的LEFT JOIN資料後,就不再搜尋。
Range checked for each Record(index map:#):無法找到理想的索引。此為最慢的使用索引。
Using filesort:當出現這個值時,表示此SELECT語法需要優化。因為MySQL必須進行額外的步驟來進行查詢。
Using index:返回的資料是從索引中資料,而不是從實際的資料中返回,當返回的資料都出現在索引中的資料時就會發生此情況。
Using temporary:同Using filesort,表示此SELECT語法需要進行優化。此為MySQL必須建立一個暫時的資料表(Table)來儲存結果,此情況會發生在針對不同的資料進行ORDER BY,而不是GROUP BY。
Using where:使用WHERE語法中的欄位來返回結果。
System:system資料表,此為const連接類型的特殊情況。
Const:資料表中的一個記錄的最大值能夠符合這個查詢。因為只有一行,這個值就是常數,因為MySQL會先讀這個值然後把它當做常數。
eq_ref:MySQL在連接查詢時,會從最前面的資料表,對每一個記錄的聯合,從資料表中讀取一個記錄,在查詢時會使用索引為主鍵或唯一鍵的全部。
ref:只有在查詢使用了非唯一鍵或主鍵時才會發生。
range:使用索引返回一個範圍的結果。例如:使用大於>或小於<查詢時發生。
index:此為針對索引中的資料進行查詢。
ALL:針對每一筆記錄進行完全掃描,此為最壞的情況,應該盡量避免。
我們可以注意到 `browse_history` 這個表單在Query中並沒有使用索引,
可以從上方的QueryString中發現該段Query的Left Join是查詢`product_id`這個欄位,前往這個Table並幫其建立Index來增加檢索效率。
步驟三的時候可以選擇複數欄位來建立Index,但是要注意的是在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
再來是在Query語句中應該注意以下事項
1.避免在索引列上進行運算, 這將導致引擎放棄使用索引而進行全表掃描。
2.不使用NOT IN和<>操作, NOT IN和<>操作都不會使用索引將進行全表掃描。NOT IN可以NOT EXISTS代替,id<>9則可使用id>9 or id<9來代替。
3.檢查where條件與order by 欄位,避免全表掃描。
4.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: 可以在num上設定預設值0,確保表中num列沒有null值,然後這樣查詢: select id from t where num = 0
5.應儘量避免在 where 子句中使用 or 來連線條件,如果一個欄位有索引,一個欄位沒有索引,將導致引擎放棄使用索引而進行全表掃描。可以拆分條件,進行子句的union all查詢,如: select id from t where num=10 or name = 'admin' 拆分 select id from t where num = 10 union all select id from t where name = 'admin'
6.in 和 not in 也要慎用,否則會導致全表掃描,如: select id from t where num in(1,2,3) 對於連續的數值,能用 between 就不要用 in 了: select id from t where num between 1 and 3,
用 exists 代替 in 是一個好的選擇: select num from a where num in(select num from b) 換成 select num from a where exists(select 1 from b where num=a.num)
7.like語句的%不要前置, 否則索引失效 將導致全表掃描。
8.如果在 where 子句中使用引數,也會導致全表掃描。 因為SQL只有在執行時才會解析區域性變數,但優化程式不能將訪問計劃的選擇推遲到執行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變數的值還是未知的,因而無法作為索引選擇的輸入項。
9.應儘量避免在where子句中對欄位進行函式操作,這將導致引擎放棄使用索引而進行全表掃描。
10.不要在 where 子句中的“=”左邊進行函式、算術運算或其他表示式運算,否則系統將可能無法正確使用索引。
11.在使用索引欄位作為條件時,如果該索引是複合索引,那麼必須使用到該索引中的第一個欄位作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應儘可能的讓欄位順序與索引順序相一致。
12.Update 語句,如果只更改1、2個欄位,不要Update全部欄位,否則頻繁呼叫會引起明顯的效能消耗,同時帶來大量日誌。
對於多張大資料量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,效能很差。
13.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
14.任何地方都不要使用 select * from t ,用具體的欄位列表代替“*”,不要返回用不到的任何欄位。
15.避免頻繁建立和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重複引用大型表或常用表中的某個資料集時。但是,對於一次性事件, 最好使用匯出表。
16.在新建臨時表時,如果一次性插入資料量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果資料量不大,為了緩和系統表的資源,應先create table,然後insert。
17.儘量拆分大的 DELETE 或INSERT 語句,批量提交SQL語句。
18.儘量避免使用遊標,因為遊標的效率較差,如果遊標操作的資料超過1萬行,那麼就應該考慮改寫。
參考來源:
1. http://blog.twbryce.com/mysql-explain/
2. https://www.gushiciku.cn/pl/gkis/zh-tw
3. https://www.itread01.com/content/1548581229.html
梨子, 2022/3/28 下午 09:00:29
老問題, 居然又查了一次, 要記下來.
看到這個要檢查 SQL command 的結尾是不是加了 ";"
只有在 Oracle 會發生的問題.
看到這個要檢查 SQL command 的結尾是不是加了 ";"
只有在 Oracle 會發生的問題.
Bike, 2021/11/3 下午 07:48:10
建立 tablespace:
有點類似 SQL 的 Create Database
create tablespace IEDF_D004M datafile 'C:\Oracle\IEDF_D004M.DBF' size 100M autoextend on next 10M maxsize unlimited;
Bike, 2021/8/4 下午 09:48:39
今天小三的網站發生怪異的情況,造成網站莫名其妙跑出天天簽到的彈跳視窗
使用 set 條件,但產出的SQL卻是沒有 where 字串,這情況我是第一次遇到
是不是產出SQL時這中間用到 static 物件,可能要查一下
-----------------------------
看樣子是網站第一次使用DB物件時,兩個 thread 同時在跑會造成這樣的現象
這裡應該要 lock
var oEM = new EverydayMain();
oEM.EndDate__StartOrEqual = DateTime.Now.Date; //只要限結束日期就好. (以日為單位)
oEM.Type = EN.Type.彈出式;
oEM.QuerySql();
// 卻產出SQL Select * from [Everyday_Main] With(NoLock)
// 但應該產出 Select * from [Everyday_Main] With(NoLock) Where [EndDate] >= Convert(datetime, '2021-07-15T00:00:00') and [EN_Type] = 200
使用 set 條件,但產出的SQL卻是沒有 where 字串,這情況我是第一次遇到
是不是產出SQL時這中間用到 static 物件,可能要查一下
-----------------------------
private static Hashtable _htTypeDefines;
public static Hashtable htTypeDefines
{
get
{
if (_htTypeDefines == null)
{
_htTypeDefines = new Hashtable();
_htTypeDefines.Add("Id", "int");
看樣子是網站第一次使用DB物件時,兩個 thread 同時在跑會造成這樣的現象
這裡應該要 lock
darren, 2021/7/15 下午 12:32:38
因為需要處裡葡萄牙文
例如 Crédito Pré...
在insert 的時候 把內容寫成 N'XXXX'
結果報錯
SQLException:java.sql.SQLException: Incorrect string value: '\xE9 XXXX' for column 'OOOOOO' at row 1
理由應該是這篇
https://stackoverflow.com/questions/10957238/incorrect-string-value-when-trying-to-insert-utf-8-into-mysql-via-jdbc
改法
https://dba.stackexchange.com/questions/8239/how-to-easily-convert-utf8-tables-to-utf8mb4-in-mysql-5-5
但解法反而是把 N拿掉就好了
這篇有說 N'XXX' 跟 _utf8'XXX' 不一樣
https://bugs.mysql.com/bug.php?id=17313
用JAVA 寫的不確定C# .NET會不會有類似情況
例如 Crédito Pré...
在insert 的時候 把內容寫成 N'XXXX'
結果報錯
SQLException:java.sql.SQLException: Incorrect string value: '\xE9 XXXX' for column 'OOOOOO' at row 1
理由應該是這篇
https://stackoverflow.com/questions/10957238/incorrect-string-value-when-trying-to-insert-utf-8-into-mysql-via-jdbc
改法
https://dba.stackexchange.com/questions/8239/how-to-easily-convert-utf8-tables-to-utf8mb4-in-mysql-5-5
但解法反而是把 N拿掉就好了
這篇有說 N'XXX' 跟 _utf8'XXX' 不一樣
https://bugs.mysql.com/bug.php?id=17313
用JAVA 寫的不確定C# .NET會不會有類似情況
sean, 2021/7/2 上午 09:55:14
試說明以下程式碼的功用, 以及可改進的部份.
--
基本題:
1. 對 Linq 熟嗎.
2. 對 ASP.Net 的 Cache 熟悉嗎.
3. 用過什麼 ORM, 試說明優缺點.
4. 試說明 MVC 的架構.
資安相關問題:
1. 試說明 SQL Injection
2. 試說明 Cross Site Injection.
3. 上傳檔案要注意的事項.
4. 試說明 cookie 的安全設定 ? same site, secure, http only.
前端相關加分題:
1. jQuery 或 Vue 熟悉嗎 ?
2. 試說明 RWD
3. 試說明 bootstrap
進階問題:
1. 試說明 Reflection
2. 試說明 Dependency Injection
3. 試說明 singleton vs static
4. 試單有兩個欄位 Id, Status (付款待確認: 1.1; 已付款: 2, 訂單已出貨: 3; 訂單取消中: 5; )
狀態 1.1 和 狀態 2 的訂單可取消,取消後改為狀態 5
客人要取消訂單,訂單編號為 123, 試說明程式執行的過程。
string EndDate = Request["EndDate"];
DataTable qtyControls = U2.SQL.DTFromSQL("Select YA00, PD00 from QtyControl Where EndDate > '" + EndDate + "' and SoldQty >= InitQty");
var values = qtyControls.AsEnumerable().Select(r => "('" + r.Field<string>("YA00") + "','" + r.Field<string>("PD00") + "')").ToList();
var sqls = new List<string>();
sqls.Add("Delete StopSaleYAP;");
int start = 0;
while(start < values.Count)
{
var end = start + 999;
if(end > values.Count - 1)
{
end = values.Count;
}
sqls.Add("insert into StopSaleYAP(YA00, PD00) Values" + string.Join(",", values.GetRange(start, end)) + ";");
start = end + 1;
}
U2.SQL.ExecuteSQL(string.Join("\r\n", sqls));
public static bool IsErrorOrder(Order.Input.CheckValidOrder dto)
{
if (dto.OrderNos == null || dto.OrderNos.Count == 0)
{
return false;
}
var orderCount = dto.OrderNos.Count();
var orders = NpreoOrderMain.GetList(dto.OrderNos);
if (orders.Count != orderCount || !dto.OrderNos.Any(x => orders.Select(o => o.Order_No).Contains(x)))
{
return true;
}
return false;
}
var fu = Request.Files[0];
fu.SaveAs(Server.MapPath("UploadFiles/") + fu.FileName);
--
基本題:
1. 對 Linq 熟嗎.
2. 對 ASP.Net 的 Cache 熟悉嗎.
3. 用過什麼 ORM, 試說明優缺點.
4. 試說明 MVC 的架構.
資安相關問題:
1. 試說明 SQL Injection
2. 試說明 Cross Site Injection.
3. 上傳檔案要注意的事項.
4. 試說明 cookie 的安全設定 ? same site, secure, http only.
前端相關加分題:
1. jQuery 或 Vue 熟悉嗎 ?
2. 試說明 RWD
3. 試說明 bootstrap
進階問題:
1. 試說明 Reflection
2. 試說明 Dependency Injection
3. 試說明 singleton vs static
4. 試單有兩個欄位 Id, Status (付款待確認: 1.1; 已付款: 2, 訂單已出貨: 3; 訂單取消中: 5; )
狀態 1.1 和 狀態 2 的訂單可取消,取消後改為狀態 5
客人要取消訂單,訂單編號為 123, 試說明程式執行的過程。
Bike, 2020/10/24 上午 10:24:51
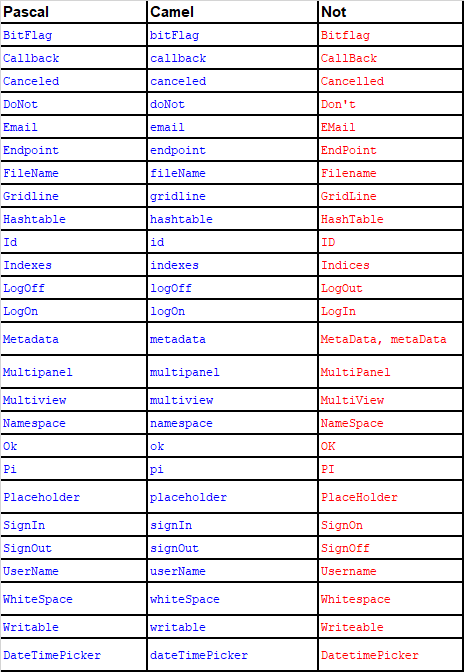
名命規則
C#:
參數, 區域變數: 小駝峰(CamelCasing)
其它: 大駝峰(PascalCasing)
參考:
https://docs.microsoft.com/zh-tw/dotnet/standard/design-guidelines/naming-guidelines
Javascript:
小駝峰(CamelCasing)
網址:
全小寫, 用 - (減號) 分隔單字
參考:
https://www.seoseo.com.tw/article_detail_609.html
https://blog.miniasp.com/post/2011/01/14/Avoid-using-underline-as-domain-name-character
http://epaper.gotop.com.tw/pdf/acn023600.pdf
class 名命 HTML :
全小寫, 用 - (減號) 分隔單字
複合字範列:
| Pascal | Camel | Not |
| BitFlag | bitFlag | Bitflag |
| Callback | callback | CallBack |
| Canceled | canceled | Cancelled |
| DoNot | doNot | Don't |
| Endpoint | endpoint | EndPoint |
| FileName | fileName | Filename |
| Gridline | gridline | GridLine |
| Hashtable | hashtable | HashTable |
| Id | id | ID |
| Indexes | indexes | Indices |
| LogOff | logOff | LogOut |
| LogOn | logOn | LogIn |
| Metadata | metadata | MetaData, metaData |
| Multipanel | multipanel | MultiPanel |
| Multiview | multiview | MultiView |
| Namespace | namespace | NameSpace |
| Ok | ok | OK |
| Pi | pi | PI |
| Placeholder | placeholder | PlaceHolder |
| SignIn | signIn | SignOn |
| SignOut | signOut | SignOff |
| UserName | userName | Username |
| WhiteSpace | whiteSpace | Whitespace |
| Writable | writable | Writeable |
| DateTimePicker | dateTimePicker | DatetimePicker |
Bike, 2020/7/28 上午 08:00:08